
通常我們在評估一個演算法的效能與優劣時,會去探討它的時間複雜度與空間複查度,就像 Jason之前在演算法系列文章裡寫的這兩篇所提及的那樣。 只不過在一個機器學習演算法當中,時間複雜度與空間複雜度固然重要,但往往並不是我們最重視的! 這麼說吧~ 如果有兩個預測天氣的模型(演算法),方法一:算的又快、耗費的資源又少,只不過準確率只有百分之五十;而方法二:不但要算很久、耗費的資源也多,但準確率卻高達百分之九十九。那麼傻子也知道要選方法二吧~ 雖然它算的慢,但只要明天的天氣預報今天之內有辦法算的出來那也沒啥問題。 看到這邊我們大概能有個 Sense 是:對於一個預測性質的任務,預測的準才是王道! Ok, 可能有人會想說,如果只是要看預測的準不準,那麼我們直接計算它的準確率(Accuracy),不就好了嗎? 那還有什麼好說的? hum.. 要這麼說也不能算錯,直接計算模型的 Accuracy 的確是一種很直覺、很快速方法,但是,它並不是在所有的狀況都會 Work。比如說,今天我們想建一個 AI Model 來預測一個人會不會得到一種罕見疾病,正常來說大部分的人是健康的,而真實擁有這種疾病的人只有百分之一。在這種狀況下,即便你的 Model 跟蛋黃哥一樣很軟爛不想工作,結果不管你 Input 什麼 Data 進來它都跟你說這個人沒病,你的 Model 還是能夠得到高達百分之九十九準確率。聽起來有點弔詭、有點荒謬吧~ 因為在應用的案例上有著嚴重的資料不平衡(Imbalanced Data),所以導致你的 Model 什麼事也不用做,就能號稱自己用有九十九趴的準確率,這不就跟那些尸位素餐中年人嘴砲我們是沒有用的年輕人一樣,怎麼想都不太合理吧? 對於搞資料科學的我們,自然是不能容忍這麼荒謬的事情。雖然數據沒有造假、也沒有算錯,那顯而易見的就是:這樣的評估方式並不恰當。因為比起正確判斷健康的人有沒有病,我們更在意那少數一趴真正有病的人能不能被模型判斷出來,其實這就是檢驗方法裡面敏感性(Sensitivity)與特異性(Specificity)的概念。所以我們就知道不該單單只是去看它的準確率(Accuracy)高不高,而是進一步依你實際應用案例的需求來決定用什麼指標來評估它,今天要講的混淆矩陣(Confusion Matrix)就是一個可以協助我們生出各項評估指標的工具。 我們一樣延續上面這個二元分類的任務(判斷是有病還是沒病)來舉例,我們需要預測的樣本中會存在所謂的正樣本(有病的人)與負樣本(沒病的人);然後我們模型可能預測它為正(有病)或者負(沒病),然後就可以排列組合出以下四種狀況:
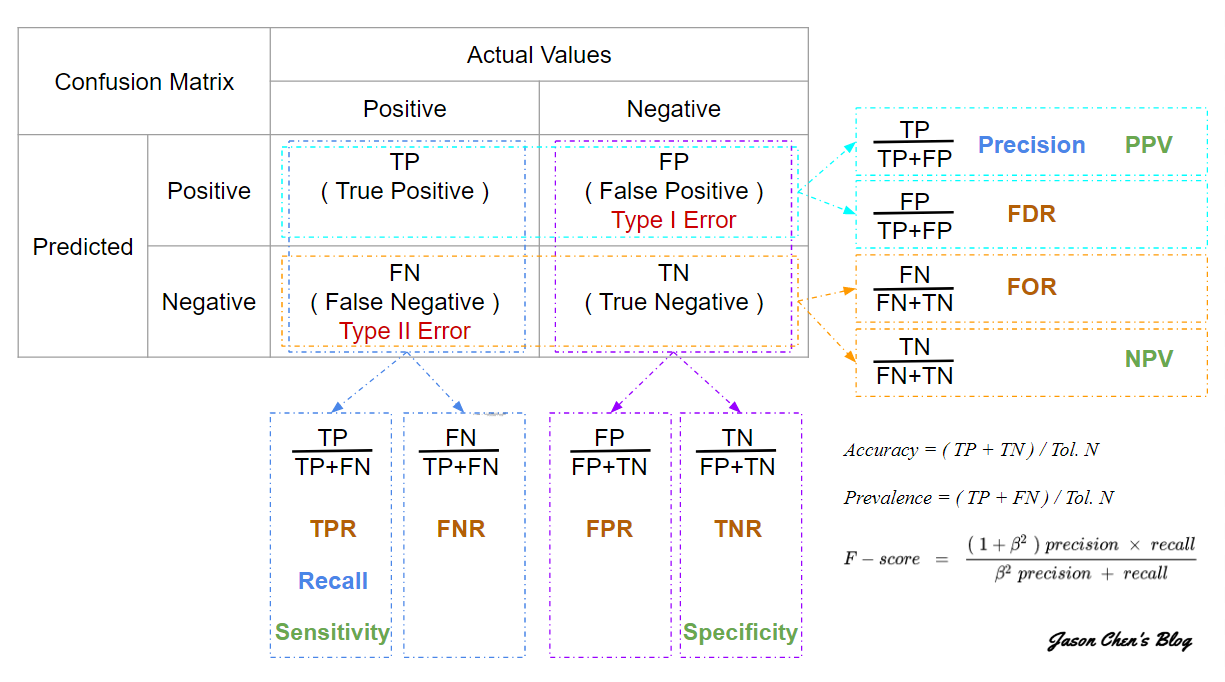
最後我們只要把模型預測的狀況,對應到混淆矩陣中就可以用來分析模型性能的好壞了!
依照上面的例子,可以算出:TP = 0;FP = 0;FN = 1;TN = 99。 如此以來我們就知道這個模型的:
既然都提到了 Sensitivity 與 Specificity,那就不得不再說一下 AUC(Area under the Curve) 與 ROC(Receiver Operating Characteristic Curve),不過基本上這東西我們都是合在一起講的,稱作:AUROC,也就是計算 ROC曲線下的面積,數值會介於 0~1 之間,該值越接近 1 表示模型辨識正樣本與負樣本的能力就越強,而一個完全隨機的分類器(沒有什麼預測的能力)其 AUROC 值會落在0.5左右,可參見下圖: 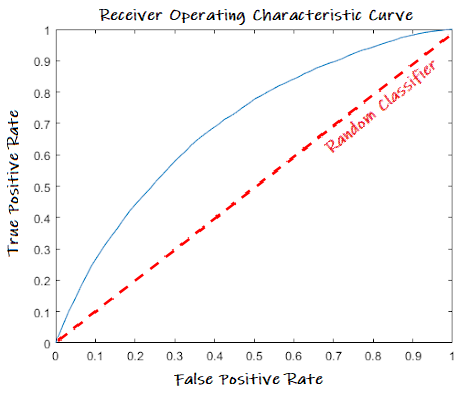
基本上我們都希望我們的模型對於正負樣本的辨識力越強越好,所以 AUROC 值就越接近 1越好,而在圖形上的表現就是曲線越靠近左上越好。
Ok, 基本上關於什麼是 Confusion Matrix 都交代清楚了,然後也介紹了一點 AUROC! 那今天這篇就寫到這邊了~ 我們下一篇再見。
0 評論
發表回覆。 |
Jason Chen人不光是生來就擁有一切,而是靠他從學習中得到的一切來造就自己。- 歌德 文章分類
全部
封存檔
九月 2023
|
