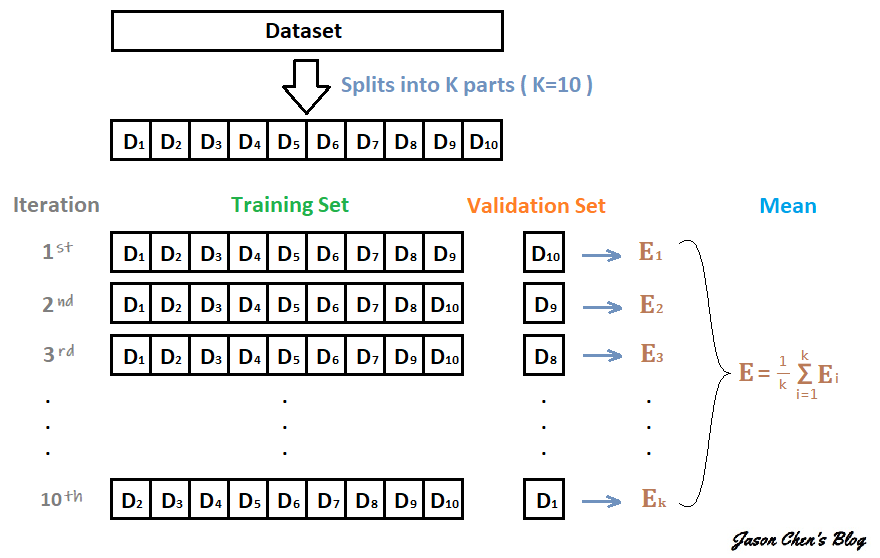
一般來說我們在做機器學習 ( Machine Learning ) 的時候,我們會習慣將資料集 ( Dataset ) 切割 ( Splits ) 成訓練集 ( Training Set ) 跟驗證集 ( Validation Set )。顧名思義,Training Set是用來訓練 Machine Learning 的 Model;而 Validation Set 則用來驗證這個 Model 訓練的好不好。 至於為什麼要這麼做的理由,Jason 在之前寫的【機器學習】偏差與方差之權衡 Bias-Variance Tradeoff 這篇中就有稍微介紹過了!因為在實務上我們很難實際去計算模型的偏差與方差,所以我們更常透過模型外在的表現來判斷它現在是 underfitting 還是 overfitting。 上面提到的外在表現就是觀察 Model 在 Training Set 跟 Validation Set 的 Error 為多少。 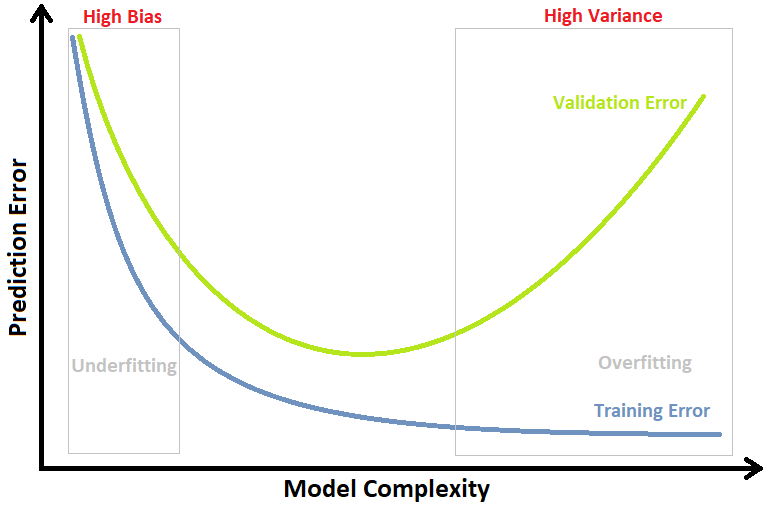
以上圖為例,如果模型複雜度偏向簡單 ( 靠近圖片左邊 ) 的時候那麼它在 Training Set 跟 Validation Set 的 Error 都非常的高,則表示說模型處於 underfitting 的狀況;而如果模型複雜度太過複雜 ( 靠近圖片右邊 ),雖然它在 Training Set 的 Error 可以降到很低,但在 Validation Set 的 Error 卻非常的高,則表示模型已經 overfitting 了。
Ok,我想一定有人覺得「阿~不就從資料集裡面切一小塊出來做驗證就好,這有啥好講的?」 沒錯在很某些情況我們只要在程式上設定一下,讓它割個 5~20% 左右的資料來當驗證集就可以了。 BUT,為什麼可以寫這篇就是因為有這個BUT!在某些情況底下 ( e.g. 小樣本 ) 單純直接從資料集裡面切一塊出來當驗證集,是沒有辦法很有效的去評量一個 Model 訓練的好壞。 我們之所以把數據集拆成訓練集和驗證集,就是要度量模型對新數據的泛化能力。畢竟我們最終的目的是應用這個訓練好的模型來做分析、預測,所以我們對模型在訓練集上的擬合的好不好並不感興趣,而是想知道模型對於訓練過程中沒見過數據的預測能力。在少量樣本的狀況下,你從當中抽出來的那一小部分驗證集資料,那些樣本資料通常已經不具代表性,所以你可能會抽到某些資料驗證出來覺得模型訓練得還不錯,但換抽另一批資料來驗證就又覺得模型訓練的很糟糕。而為了避免這個狀況,可以比較有效的來評估模型的好壞,這時候我們就會採用「交叉驗證 Cross-Validation」的方法來做驗證。 交叉驗證的方法有很多,其中最常見、經典的是一個叫做:K-fold Cross-Validation 的方法, 中文可以叫做 K 折驗證、K 折交叉驗證,但聽起來蠻怪的,建議還是講 K-fold 就好。 接下來 Jason 就對這個方法稍做介紹吧! K-fold Cross-Validation
K-fold 的 K 跟 K-mean、KNN 的 K 一樣,指的是一個數字,一個可以由使用者訂定的數字;
K-fold 的 fold 中文意思是 "折",指的是將資料集 "折" (拆分) 成幾個部分。 顧名思義 K-fold Cross-Validation 就是將資料集拆分成 K 份做交叉驗證。 交叉驗證的方法是將其中 K-1 份的資料當作訓練集,剩下來的那份做為驗證集,算出一個 Validation Error,接著再從沒當過驗證集的資料挑一份出來當驗證集,剛剛做過驗證集的資料則加回訓練集,維持 K-1 份做訓練、1 份做驗證,如此反覆直到每一份資料都當過驗證集,這樣會執行 K 次,算出 K 個 Validation Error,最後我們再將這 K 個 Validation Error 做平均,用他們的平均分數來做為我們評斷模型好壞的指標。 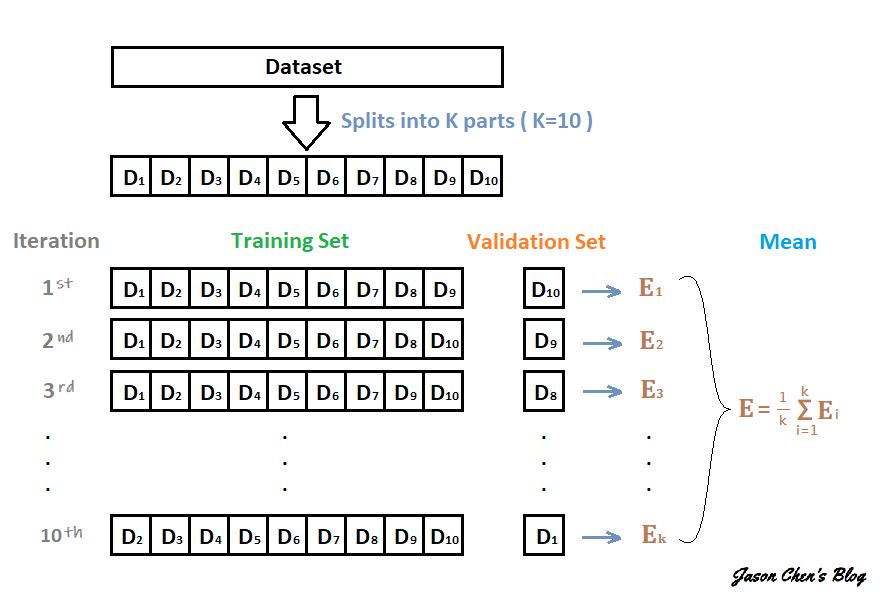
基本上它的概念還算簡單,另外附上一段使用 Python 實現 K-fold Cross-Validation 的代碼:
K-fold Cross-Validation
雖然 Cross-Validation 的觀念蠻重要的,在 Interview 的時候也常考,不過我們真的在實作機器學習的時候這部分我們通常會使用別人已經寫好的 Library 啦~ 不需要自己寫!
像是可以直接使用 scikit-learn 裡面 model_selection 底下的 cross_val_score 方法。 那今天這篇就先寫到這邊了,感謝觀看 :")
0 評論
發表回覆。 |
Jason Chen人不光是生來就擁有一切,而是靠他從學習中得到的一切來造就自己。- 歌德 文章分類
全部
封存檔
九月 2023
|
