一、簡介 Introduction
對雜亂無章的原始資料 ( Raw Data ) 進行整理、做排序的動作,在整個資料科學或者電腦編程上都是十分重要的一件工作!也正因為如此,於是就有大量的專家、學者投入研究:排序演算法。
排序演算法就跟 Jason 在【演算法】隨機亂數產生 Random Number Generation 那篇裡提到的「隨機亂數產生演算法 」一樣,雖然它們都被多數人認為是已經被解決的問題( 或者說現有的 Solution 已經足夠我們應用 ),但卻也是這看似不起眼的演算法,真正的支撐了、建構起我們的這一個文明世界。 而經歷了這麼多年的發展與研究,其實關於排序的演算法非常非常的多! 不太可能全部都知道,或者全部跟你們介紹一遍,於是挑了幾個 Jason 認為比較重要的列出來:
其實今天如果你是要 Coding,幾乎只要知道:氣泡排序、木桶排序、快速排序,這幾個就非常夠用了。所以接下來會針對這幾個做比較詳細的介紹,至於如果你是要 Job Interview、還是考研的話,可以參考另外兩篇: 【演算法】插入排序與希爾排序 Insertion & Shell Sort 【演算法】選擇Selection | 合併Merge | 堆積Heap 排序法 二、氣泡排序 Bubble Sort
Bubble Sort,有人叫它氣泡排序、也有人叫泡沫排序或泡泡排序,其實都是一樣的,就是Bubble Sort。它算是一種非常簡單的排序演算法,也很容易實現。它演算法的想法是,從頭開始走訪我們要進行排序的數列,然後每次比較數列中相鄰的兩個元素,如果他們大小順序錯誤的話就讓他們互換,如此重複到再也沒有需要交換,即代表排序完成。演算流程如下方 gif 所示:
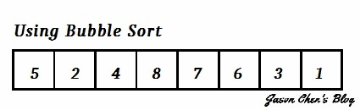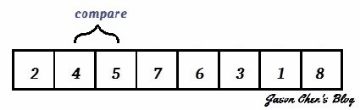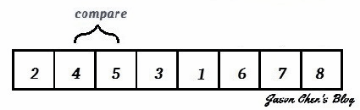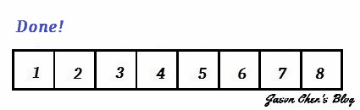
你可以看到,其中比較大or比較小 ( 取決於你要從小排到大;還是從大排到小 ) 的元素會被慢慢換到數列的最前面,這個過程就像水中的小泡泡慢慢浮上水面一樣,所以叫Bubble Sort。而也因為它簡單、易實現的特性,所以一般學生們都很愛用,像 Jason 在這篇 【影像處理】雜訊與濾波 Noise and Filter 裡面實作 Median Filter 及 Alpha Trimmed Filter 用的排序就是 Bubble Sort。
我們在討論一個演算法優劣的時候,通常我們會考量它的時間複雜度 ( Time Complexity ) 跟空間複雜度 ( Space Complexity )[註一],其中特別是時間複雜度的部分,因為如今硬體越發便宜,一般裝置擁有的記憶體都變得很大了,除非是在一些比較特別的 case 不然其實空間複雜度的部分越來越少人在討論了。 那我們稍為來計算一下 Bubble Sort 的時間複雜度,如果今天有一個數列裡面含有N個元素,那麼它平均的時間複雜度會是:O( N^2 )。 【程式碼下載】 三、木桶排序 Bucket Sort
Bucket Sort 演算法的想法是,將欲進行排序的 Raw Data 先分裝到有限數量的桶子裡面 ( 一般我們會把它切割成一個區段一個區段 ),然後各個桶子裡面的東西再各別進行排序,可以用別的排序演算法或者用 Call 遞迴的方式再用桶排去排。最後再將各個非空的桶子排序完的結果進行合併,就是我們最終要的答案。
如下示意圖: 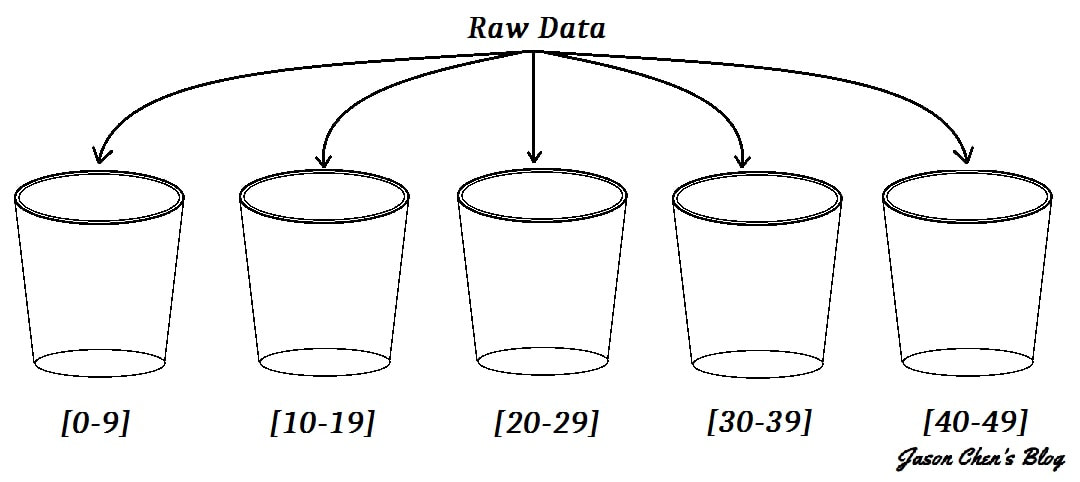
假設我們的 Raw Data 有N筆數值介於 0 ~ 49 的資料要進行排序,我們可以把它切成數個區間,上圖的例子中將它拆成了五個區間 [0-9]、[10-19]、[20-29]、[30-39]、[40-49],然後我們會把資料丟進對應的區間。
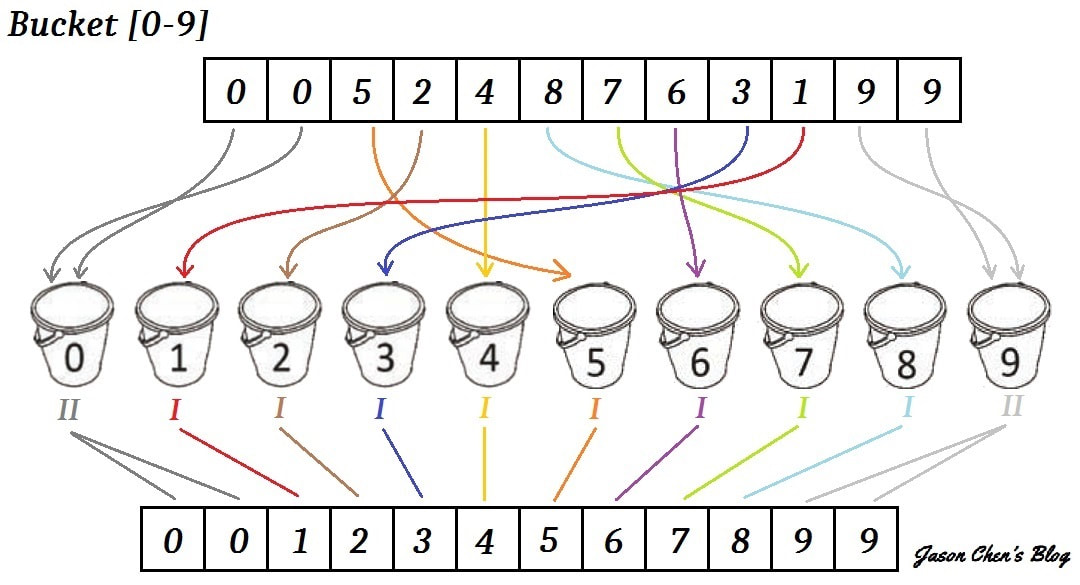
上圖是針對一開始分出來的 [0-9] 這個子桶,再用桶排進行排序的過程。
在各個子桶都各別完成排序以後,最後只要再將其結果進行合併就可以了。 Bucket Sort 算是十分簡單且常見的排序演算法,跟 Bubble Sort 比起來桶排算快非常多,它的平均時間複雜度為:O(n),但是相對的它也多付出了很多空間複雜度。 【程式碼下載】 四、快速排序 Quick Sort
Quick Sort 其實它還有一個名子叫作:規劃交換排序 Partition-Exchange Sort,雖然看到這個名子你比較能想像這個演算法再幹嘛,但是我們一般都還是習慣稱它作快排。
快排它採用了一個在演算法當中相當重要的概念:Divide and conquer,中文應該叫作分治法吧? Divide and conquer 的精神就是,分而治之、各個擊破! 當今天你沒有辦法將一整把筷子一次折斷的時候,那我們分成一隻一隻折總行了吧! Divide and conquer 的作法就是這樣,會把比較困難的大問題,拆成數個比較簡單的子問題來解。 基於這個策略,Quick Sort 會將要進行排序的序列( list ) 分割成兩個子序列( sub-list ),步驟為:
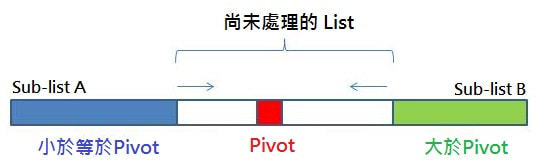
接著我們遞迴地把剛剛拆出來的 sub-list 繼續做 Partition,直到一路遞迴到最底部時,sub-list 的大小是0或1,那也就是代表說已經排序完成了。
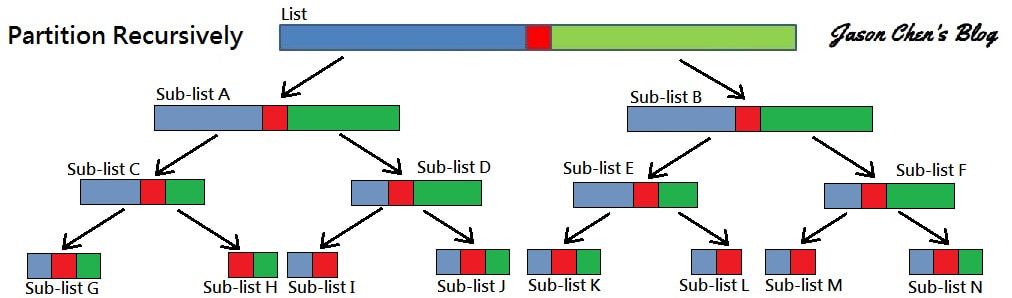
這麼做到最後一定會結束,因為在每次的疊代 ( iteration ) 的過程中,至少會把一個元素擺到它最後的位置去。Quick Sort 的效率和基準值 ( Pivot ) 的選擇息息相關,每次選擇的基準值 ( Pivot ) 如果愈接近 List 的平均值或中位數愈好。 我們在基準值 ( Pivot ) 的選擇上,一般有以下幾種策略:
在平均狀況下,Quick Sort 排序 n 個項目要 O( n log n ) 次比較,事實上,快速排序通常明顯比其他演算法更快,因為它的內部迴圈 ( Inner loop ) 可以在大部分的架構上很有效率地達成。 【程式碼下載】
[註一] 時間複雜度、空間複雜度:是兩種用來衡量程式好壞的客觀指標,通常兩者是相互 Trade off 的。對一個 Programmer 來說,這算是非常重要的基礎之一,Jason 有再寫一篇來詳談這個部分。
0 評論
發表回覆。 |
Jason Chen人不光是生來就擁有一切,而是靠他從學習中得到的一切來造就自己。- 歌德 文章分類
全部
封存檔
九月 2023
|
