What is Kaggle?
Kaggle 成立於2010年,是一個進行資料探勘和預測競賽的在線平台,也是全世界公認最大的資料科學社群。基本上它隨時都有各式各樣的資料分析比賽在進行,而這些比賽常常都會提供一些高額的獎金 ( 這些獎金由企業提供約 5,000 - 10,000 USD,因為通常比賽要解決的問題就是他們現在真實遇到的狀況。);除了這些小比賽之外,Kaggle 官方每年還會舉辦一次大規模的競賽,它的獎金則高達一百萬美金。所以就會吸引來自世界各地優秀的 AI 工程師、資料分析師、資料科學家 或一些學生、研究人員等前來參賽。
或許我們的能力還不足以跟世界頂尖的人一較高下,但在 Kaggle 裡最棒的是有許多熱愛分享的人,在比賽結束後會於討論區當中留下他們當初思考這個問題的邏輯思路與解題脈絡,有的甚至會提供你整包 Github 的代碼,看看這些高手們是怎麼解題的對自己各方面能力的提升都有很大的幫助! Let's be a Kaggler!
通常我們在學習一門新的程式語言的時候,會寫的第一支程式叫做:Hello World!主要是用來驗證基本的運行環境是否正常,同時也代表我們打開了一扇通往程式新世界的大門,並跟這個世界打聲招呼。
而在 Kaggle 上的競賽有非常多不同的類別,有的項目對剛入門的新手來說並不是那麼友善,所以通常我們想成為一個 Kaggler 並在 Kaggle 上實作第一個競賽來 Hello Kaggle 一下的時候,會選一個名為 Titanic ( 沒錯就是那艘歷史上有名,還被翻拍成電影的沉船 Titanic ) 的挑戰來做,而這個挑戰要做的就是,船上乘客的生存預測。 Ok, 那接下來 Jason 會簡單的帶大家來做一下 Titanic 這個挑戰: Step 1. 註冊 Kaggle 帳號
Step 2. 下載資料集 Download Titanic Dataset
Step 3. 觀察資料集 Observed Dataset 一般在正式開始做 Data Mining 或 Machine Learning / Deep Learning 之前,我們會先觀察我們接下來要使用的 Dataset 長的是怎麼樣,像是它有多少筆資料、有哪些維度的資料、每個維度的資料分別是什麼型別的、有沒有 Missing Data 等等,以便後續做「特徵選取」與「資料前處理」,避免發生 Garbage in ,Garbage out。 下載下來的資料集裡面會有一個 train.csv 及一個 test.csv ,train.csv 是給我們用來訓練模型使用的; 而 test.csv 則是我們需要預測的;最後我們會將預測的結果存在一個 submission.csv 上傳到 Kaggle。 接著我們會針對 train.csv 來進行觀察,此時我們可以寫一隻簡單的 Python 程式將 train.csv 用 ( Pandas ) Data Frame 的型態將資料讀入後,再使用 ( Pandas ) build-in 的 function .info() 觀察到: 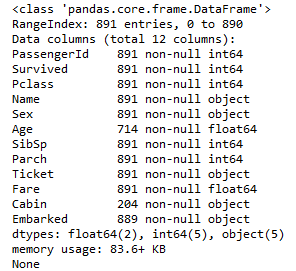
這個時候我們可以觀察到,這份資料集共有 891 筆資料,並且它在 Age、Cabin、Embarked 這三個欄位有 missing data;然後我們可以用 .describe() 來看一下資料的統計數據:

接著為了能夠更好的理解每個欄位的意義我們把頭15筆資料列印出來做觀察:
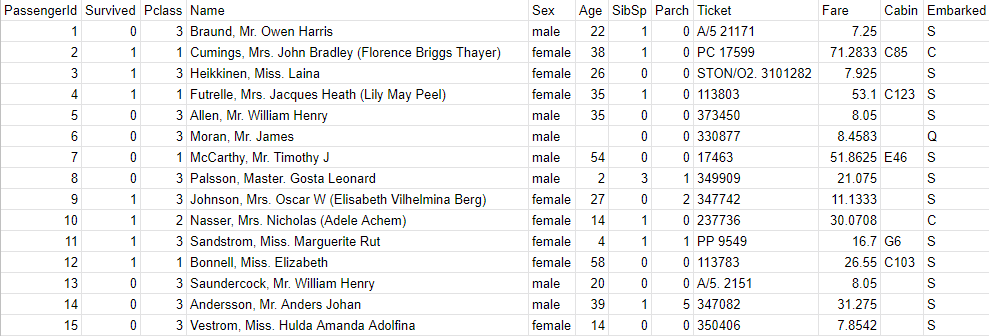
這時候我們可以觀察到,這份資料集共有12個欄位,每個欄位代表的意義如下:
其中將 Survived 這欄為答案扣除掉之外,剩下的11欄我們可以拿來做為輸入特徵使用,但是像 Passenger ID 這種流水編號,除非一開始在編號的時候就有依據某一種方式排序過,不然通常是不具任何意義的,我們也就會將其給排除!然後 Name、Ticket、Cabin 這三項屬於文字資料,觀測的方法比較 tricky 我們先暫且不看,所以就先針對剩餘的欄位去進一步觀察每一個欄位與生存率之間的關係:
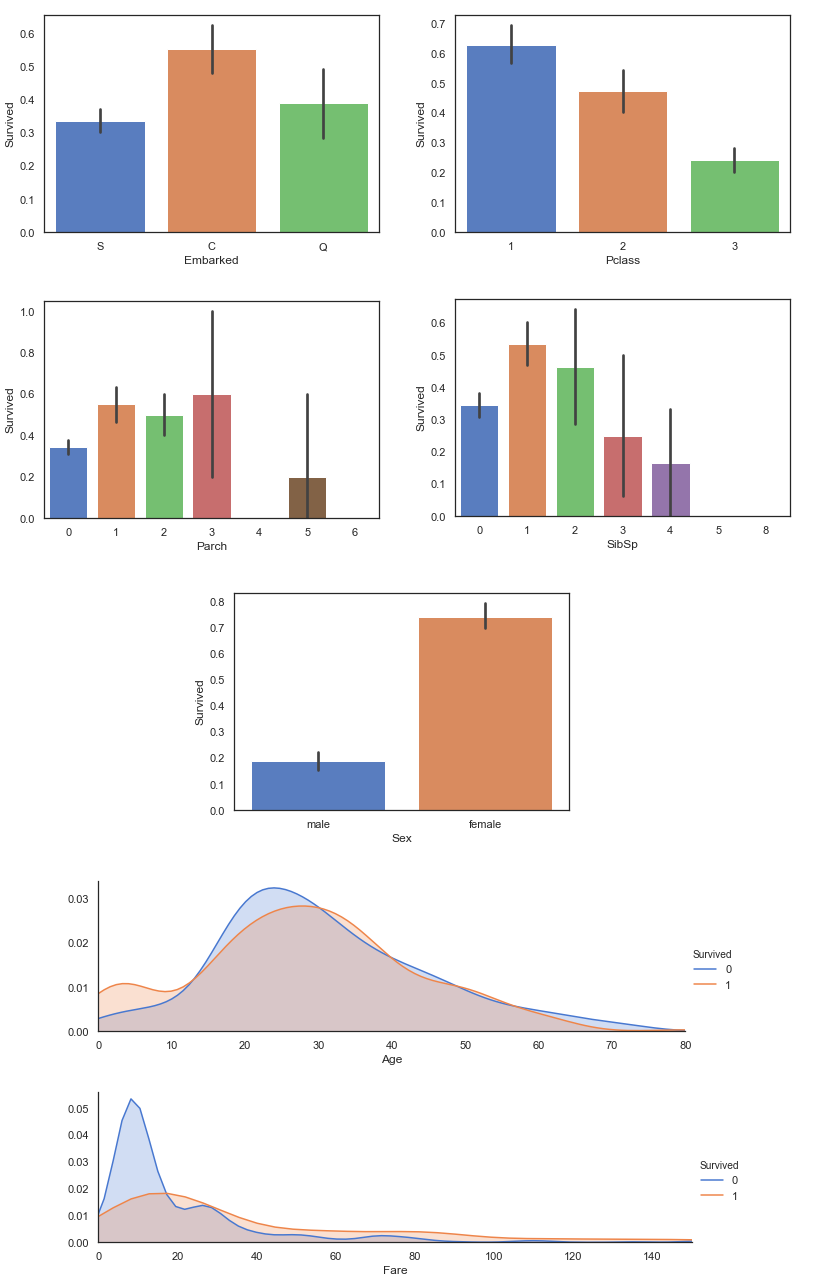
從圖表上可以看到:
上列從圖表中觀察到的 2-7 點還算好理解,但是關於第一點 "從 C 港口登船的生存率比較高",這有一點違背了我們的認知 ( 沒道理在海上發生船難時,從某一個港口登船的人會比另一個港口登船容易生存。) 但的確在圖表中是有觀察到這一個現象,那很可能是其背後有一些變量在影響 ( maybe 該港口地區的平均所得比較高,比較負擔比較好的艙等。) 既然有這樣的懷疑,那我們就將登船港口與艙等的資料拿出來分析比較一下,驗證自己的推測: 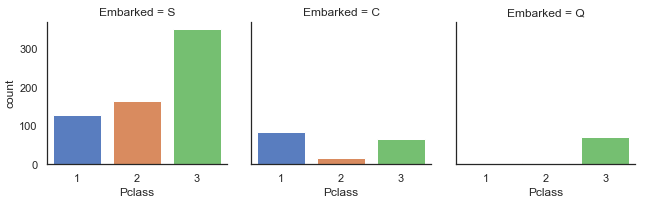
發現,的確從 C 港口登船的人大部分都是高艙等的!
算是有符合了剛剛的推測,那麼感覺登船港口這項資訊應該是沒那麼有用,就暫時先不用。 Step 4. 特徵選取 Feature Selection 為了讓 Machine Learning Algorithm (or Model) 跑出一個比較好預測的結果,我們會希望餵進 Model 的 Input 都是有效的特徵(feature);如果餵進去無效的特徵,它們就像雜訊(noise)反而會影響系統的準確性。所以特徵選取這個步驟,在 Machine Learning 裡面可說是相當重要,因為它會直接影響你模型預測準確率(Accuracy) 會飛天還是仆街。 也因為這個環節不論是在 Data Mining 或 Machine Learning 領域中都太重要了!所以關於這個部分也被開發出一套完整的方法,稱做:「特徵工程 Feature Engineering」;而特徵工程不單單只是從現有的 Feature 裡面選出有效的 Feature ,它甚至還可以利用一些方法來創造新的特徵 ( 利用現有的資料做一些整併之類的 ),此外它也包含了將 Feature Scaling ( 使得比較容易計算 ) 或將 Categorical Data 透過一些 Encoding 的方法轉成 Numerical Data 等等,基本上特徵工程就是包含了把資料餵進 Model 之前要做的全部事情。 特徵工程的東西還蠻專業的,Jason 在這邊就不詳談了,如果之後有機會再專門寫一篇來講這東西。 所以我們這邊就基於 Step 3 的觀察來做特徵選取,最後選擇:
Step 5. 數據前處理 Data Preprocessing
Machine Learning 的 Model 說穿了就是一個 Function,而它也只會做數學的運算,所以我們這個部分要做的事情就是把剛剛 Step 4 選好的特徵透過適當的處理,以便能順利的餵進 model 做運算。 都知道電腦是計算機了,只會做數學運算,那當然就只會算數字,不懂得什麼是男生、女生,這種類別型態的資料 ( Categorical Data ),所以這個時候我們就會利用一種叫做 One-hot encoding 的編碼方式做轉換,經過轉換之後它就會變成數值型態的資料 ( Numerical Data )了! 另外我們在 Step 3 的時候有觀察到,我們現在要用到的其中一個特徵 Age 是有 Missing Data 的,所以這部分我們需要將缺失值給補齊,不然餵進 model 的時候會有問題 ( 絕大多數的 Machine Learning Model 都沒辦法很好的處理缺失數據 )。 至於補值的方法有很多,通常我們觀察該缺失資料有什麼特性,再依據它的特性選擇比較適當的方法來做。 像如果缺失資料是呈現高斯分布的,那我們可以預期大部分的資料是會落在高斯分布一個標準差以內的,那麼這個時候最簡單的補值方法就是取平均。 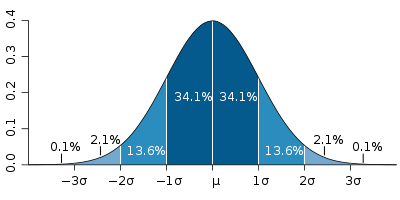
高斯分佈
雖然取平均這個方法既直覺、計算上也簡單,但在實際應用上可能也不是一個那麼好的方法。
像在 Titanic 這個例子裡,年齡缺失的資料約佔總資料的 20%,在單純計算平均將數值補上後往往會造成分佈模型的偏差 ( 見下圖 ),好一點的作法像是可以利用其他欄位來預測缺失的年齡值。 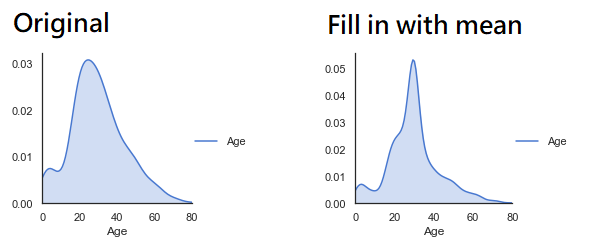
在我們把 Categorical Data 都轉成 Numerical Data 以及填補完缺失值之後事情也還沒完,雖然他們都已經是數字而且沒有缺失了,但是你會發現每一個輸入特徵的範圍都不太一樣,這樣會導致電腦在計算上它把某個特徵的權重修改一點點,就會影響很多;或是有的特徵的權重明明已經改很多了,卻才影響一點點,雖然這樣也不是說不行啦~ 但就經驗上來說,往往會導致 model train 的不好,所以我們通常還會再做一個叫做 Feature Scaling 的動作。說穿了就是幫這些已經變成樹值的特徵做 Normalization 的動作 ( 把範圍縮放到0-1 之間 )
到此數據前處裡的動作大致到一的段落,接下來就可以把準備好的數據餵進 Machine Learning 的 Model 了! Step 6. 算法模型選擇 Model Selection 講白了所謂的 Model Selection 就是:
一般來說,每個不同的 Machine Learning Model 對於都有一點假設在裡面,可能像是它假設資料的分佈是高斯分佈,而當今天你的資料真的剛好就是呈現高斯分佈的話,那麼做出來的效果可能就會蠻不錯的;反之如果你的資料不是高斯分佈,而是另一種其他的分佈那麼做出來的效果可能就沒那麼好了。 我個人能給的建議也就是,多學多試多累積! Step 7. 上傳預測結果 Upload Forecast Results Ok, 基本上這六步做完就沒你的事了,再來就是交給電腦做運算。 在電腦計算完、Train 完 Model 之後我們會再用一些指標來判斷說這個 model train 的好不好,具體用哪一個指標取決於你的問題,有的看 Overall Accuracy 就可以了,有的我們就要把 Confusion Matrix 算出來,然後可以用它再去算一些衍伸的指標 ( e.g. Precision、Recall、F1 Socre )。 既然是入門挑戰我們也不需要搞得太複雜,簡單看 Overall Accuracy 就好了! 如果用指標一看,發現 Model Train 的不好,那你就又有事做了! 可能就要開始分析問題出在哪裡,然後返回 Step 3 重新開始。 ( 大部分人做出來的成績都落在0.7~0.8 之間,能做到這個程度就可以了。) 如同我們前面所提到的要把預測的結果存成 .csv 檔然後上傳,檔案裡面會有兩欄: 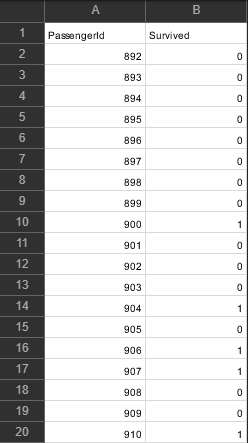
將答案上傳到 Kaggle 之後,即可看到你在這場競賽中的排名。
這東西是 Jason 幾個月前剛開始學 Machine Learning/Deep Learning 時候做的吧~
排名 1323/11432 ( 約Top 12% ) 成績不算特別好,畢竟也只是一個入門的練習競賽,不是什麼生活上真的遇到的難題,也就懶的再去改它了 xD Ok, 那這篇寫到這邊也算 High Level 的講了一遍要怎麼來做這一個 Kaggle 的入門競賽, 至於程式碼的部分由於當初寫的比較 Rough,可能之後改一改補個註解再弄個連結給需要的人參考吧。
0 評論
發表回覆。 |
Jason Chen人不光是生來就擁有一切,而是靠他從學習中得到的一切來造就自己。- 歌德 文章分類
全部
封存檔
九月 2023
|
