對於有學習過統計學、人工智慧、機器學習的人來說,你跟他提到「降維」這兩個字,他腦海中閃過的第一個方法一定就是「主成分分析(Principal Component Analysis, PCA)」,它是由100多年前的英國數學家 Karl Pearson 所發明至今仍在機器學習與統計學領域中大放異彩的資料分析方法,主要用於降低資料維度以及去關聯的線性降維方法,可謂是經典中的經典沒有之一。 那麼問題就回到,什麼是「降維」? 其實顧名思義我們就可以知道,它是要降低、減少資料的維度,但是又不能影響資料原本的 "特性"。比如說我們並不希望一個原本在三維空間呈現高斯分布的資料,在被我們降維以後就變成隨機分布了,我們會希望它基本上還是維持高斯分布的樣子。 那麼又是為什麼要「降維」? 其實呢,數學的本質是把複雜的問題變簡單,而不是把簡單的問題複雜化。「降維」的本質亦同,它想做的就是降低問題的複雜度,有點像今天你去 Interview 面試官就說:不要跟我整那些花里胡哨的,能不能用最簡短的方式介紹你自己? 大概是這樣的感覺,然後舉個具體一點的例子吧~ 其實在傳統影像處理裡面我們也很常做「降維」這件事情,就是:彩色轉灰階 RGB to Gray。 
雖然一張影像在彩色轉灰階的過程中會遺失掉大量的資訊,但在灰階影像中也很大程度的保留了原始影像中的一些邊緣、形狀、紋理以及強度變化等等資訊。所以在一些不需要色彩資訊的應用上,這樣的灰階影像就很夠我們用了,而且問題也就變得比較簡單了,相對的演算法也會比較好開發。
Ok 我想看到這邊,你們應該也能比較直觀的理解「降維」這件事了! 然後在機器學習裡面,我們做降維有一個重點是可以用來規避「維度詛咒 Curse of Dimensionality」。 另外在特徵工程裡面,也常常把它當作一種提煉特徵的方法來使用。 接著來聊聊今天的主角:主成分分析 PCA 吧!它有三個最主要的精神:
(1)計算數據的協方差矩陣; (2)計算該協方差矩陣的特徵值和向量; (3)通過特徵值和向量來只選擇最重要的特徵向量,然後將數據轉換為這些向量以降低維度。 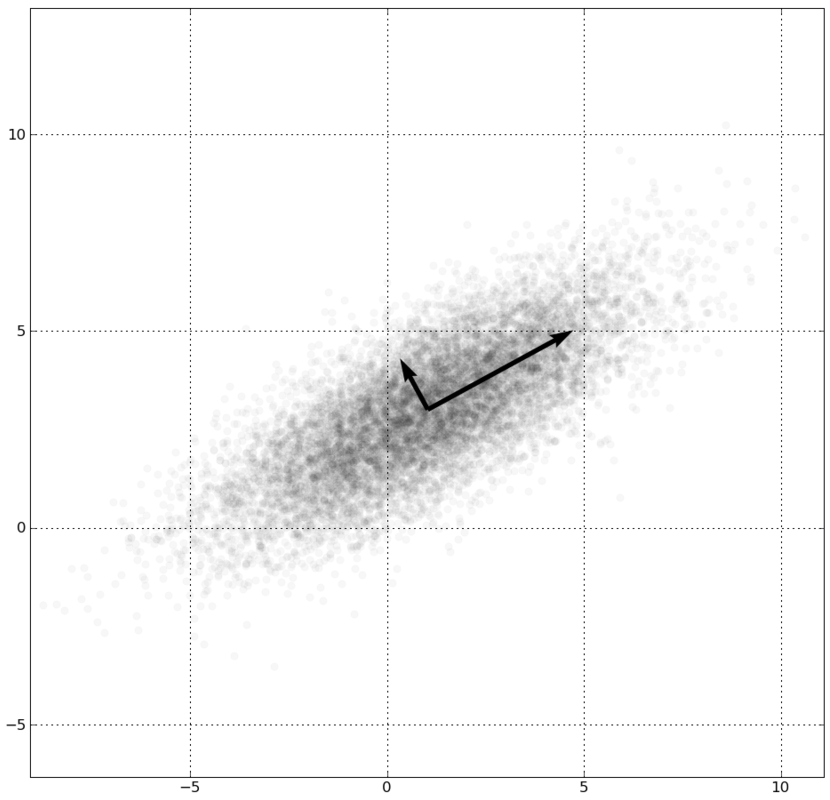
Ben FrantzDale (talk) (Transferred by ILCyborg) - I created this work entirely by myself. (Originally uploaded on en.wikipedia)
上圖是維基百科上的範例為一個高斯分布,平均值於(1, 3),標準差在(0.878, 0.478)方向上為3、在其正交方向上為1的主成分分析。黑色的兩個向量是此分布的共變異數矩陣的特徵向量,其長度為對應的特徵值之平方根,並以分布的平均值為原點。
看到這邊是不是覺得 Jason前面寫的那些你好像都還看的懂,但一到維基百科範例那邊就矇掉了? 我想這應該是多數人的反應啦~ 第一次聽到 PCA 這東西,感覺它好像很厲害、很有趣,結果上網一查找到的網頁、文件、部落格文章、線上課程等等,都寫了、講了一堆數學 or 你沒看過的名詞,讓你都不禁懷疑自己是看不懂中文還是數學不好了xD 這也蠻真實的啦~ 畢竟它底層的數學原理如果你沒學過一點統計學、線性代數還真的看不懂。 Jason 這邊就換個方式來跟大家講這個東西,如果不提數學的話那大概就剩兩個重點,分別是:
一樣我們用一個影像處理的例子來讓各位更好理解「投影」這件事。 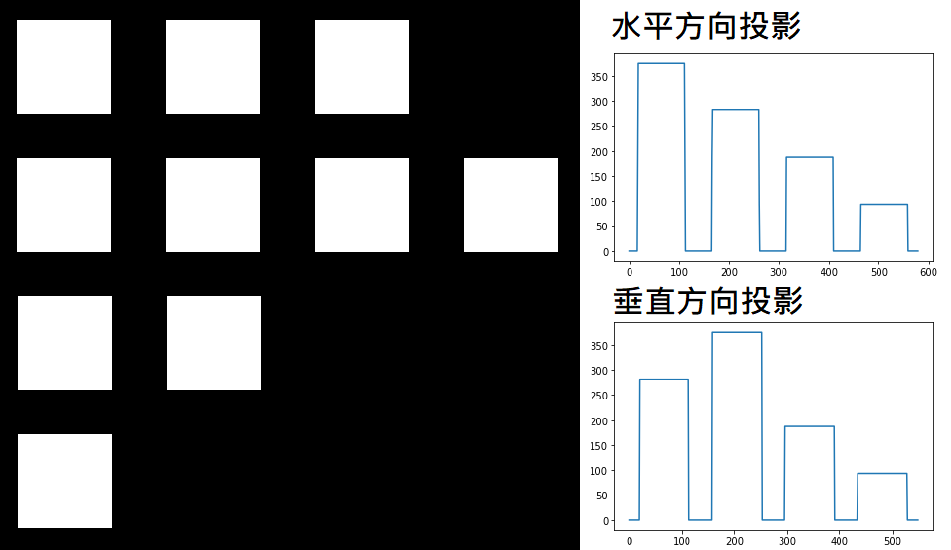
左圖是一張人工設計的黑白影像,右邊則是我把這張二維的影像根據垂直與水平兩個方向各別投影到一維向量中的結果。看完上圖後,應該就能夠很直觀的理解「投影」做的事,再來另一個重點「旋轉」其實指的就是投影的方向,投影的時候它不一定要像上圖那樣用垂直、水平的方向來投影,它可以是任意角度的。
「橫看成嶺側成峰,遠近高低各不同。」在處理資料上亦如是。 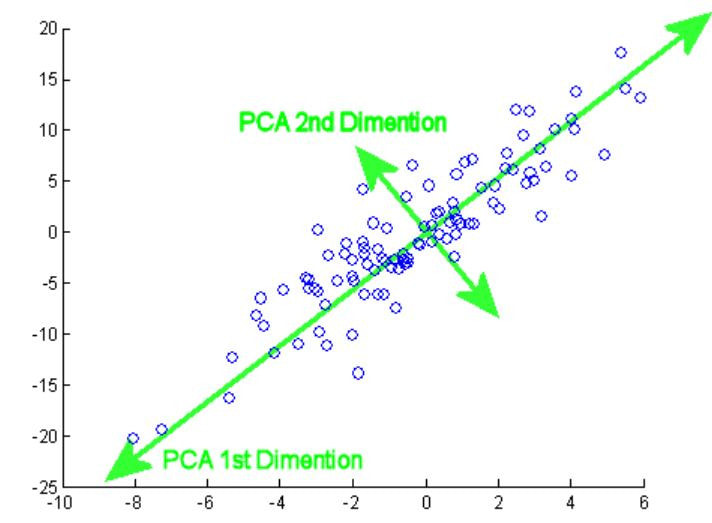
基本上的概念就是這樣,而 PCA 做的事就是拿你的資料,配合它底下複雜的數學原理做計算(上面提到的三大步驟),幫你找出它認為最好(上面提到的三大精神)的投影方向來投影。
最後在這個年代,其實我們也不需要重複的造輪子,只要站在巨人的肩膀上前行就可以了。 PCA 這麼經典的方法,自然很多 Data Science Library 都會把它包含在裡面搂~
Scikit-learn PCA Demo
相關的資源有很多啦~
Scikit-learn 我覺得算是一個在做 Data Science、Machine Learning 時非常好用的一個 Library。 使用上還蠻簡單的,如果想更清楚的了解 Scikit-learn 裡面的 PCA 要怎麼用,可以參考註解裡面的文檔。 我想這篇寫到這邊應該是差不多了,好了那就下一篇再見了 Bye~
0 評論
發表回覆。 |
Jason Chen人不光是生來就擁有一切,而是靠他從學習中得到的一切來造就自己。- 歌德 文章分類
全部
封存檔
九月 2023
|
