
孿生神經網路 Siamese Neural Networks 如果你的中文不是太差的話,看到「孿生」這兩個字應該會知道它指的是「雙胞胎」,那可能就有人會想了,雙胞胎? 啥意思? 長的一模一樣? Bingo Bingo 思路基本上對了!說穿了,所謂的孿生神經網路,就是由兩個權值共享(Shared Weights)的子網路所建構出的一個網路,如下圖所示: 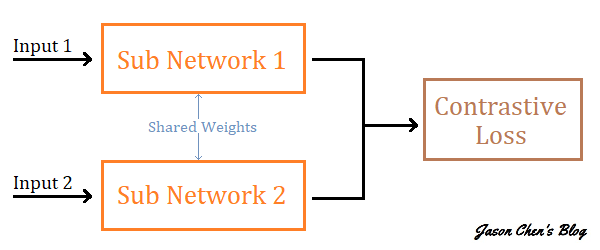
看到這邊可能有人會有個疑惑,共享權值? 兩個子網路的權重都一模一樣? 那不就是同個網路嗎? 是的!所以一般我們在實作的時候,用同一個網路就可以了,不用再特地實現另一個子網路出來。 那可能有人看到這裡就更不解了,所以像它這樣把兩個一樣的子網路拼在一起到底有啥用? 如果要一言以蔽之的話就是:用來比較兩個輸入之間的相似度。具體一點來說就是,孿生神經網路會有兩個輸入(Input 1、Input 2),各自餵進兩個神經網路(Sub Network 1、Sub Network 2),讓神經網路來做一個類似特徵轉換、特徵提取的動作,將輸入映射到一個新的特徵空間(其實這部份就有點類似在 NLP 裡面透過神經網路做 Word Embedding,把 Input 的詞語映射到一個新的向量空間的感覺。),最後我們透過 Loss 的計算來評斷兩個輸入之間的相似度。 講到這邊,可能還是有缺乏想像力的小夥伴,不明白計算兩個輸入之間的相似度到底能幹嘛~? 以最早1993年那篇論文來說的話,是把它應用在美國支票上的簽名驗證: 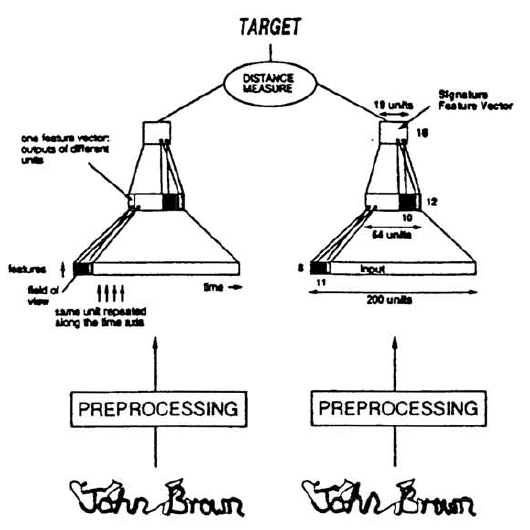
Bromley, Jane, et al. "Signature verification using a “siamese” time delay neural network."
但老實說它能做的應用實在是太多太多了,你們也可以自己發想,這邊 Jason就隨便舉幾個例:
不然我上面提到的很多應用情境不論是 Face Recognition、Object Tracking 還是 Defect 都有其他的機器學習方法可以做啊~ 它們不香嗎? 為什麼要用孿生神經網路? 這麼說吧~ 孿生神經網路跟其他的機器學習演算法是有本質上區別的!一般的機器學習演算法我們可能是讓它做分類(Classification)、回歸(Regression)、聚類(Clustering)或者降維(Dimension Reduction),而孿生神經網路做的並不是上述的這些事情,它僅僅只是在比較兩個輸入之間的相似度。若我們以人臉辨識任務為例,在傳統的機器學習技法它算是一種分類的任務,在理論上多數的分類演算法應該都要能 Handle 它,但在實務上並不然,其原因往往出在於資料集。在一個人臉辨識任務,我們往往需要分辨成千上萬個類別,單單這點對於一般的分類演算法就是一種挑戰,更別說伴隨著資料不平衡(Imbalanced Data)以及每個類別都只有極少量的訓練資料,導致你今天有再好的分類演算法都難以訓練。 而孿生神經網路就很好的避開了這些問題(因為它從頭到尾也就只管兩個輸入到底是像或不像),變成說如果你今天要檢測這個人是誰,只要拿他的臉用孿生神經網路跟你資料庫中每個人的臉比對過一次,然後判斷像不像就能知道這張臉是誰了!所以說最極限的狀況,每個類別只要一張圖片它就可以 work 了,故孿生神經網路也被歸類成一種單樣本學習(One-Shot Learning)的方法。 那除了雙胞胎之外,還有三胞胎、四胞胎 or 五胞胎嗎? 答案是.. 有的!不過好像只有搞到三胞胎而已,再高的就沒見過了。 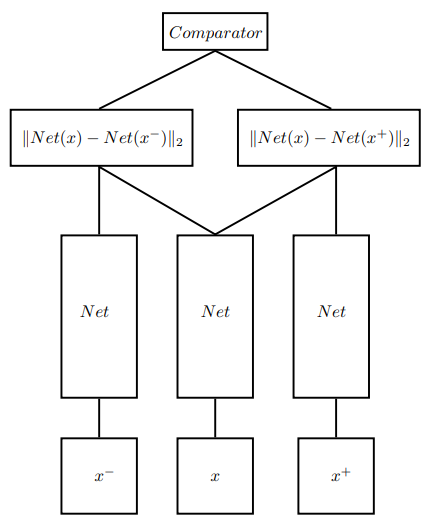
Hoffer, Elad, and Nir Ailon. "Deep metric learning using triplet network."
基本上它就是基於孿生神經網路的架構進行改進,將網路的輸入與子網路都改成三個,藉由輸入一個正樣本 + 兩個負樣本 or 兩個正樣本 + 一個負樣本來增加不同類之間的距離與縮小同類之間的距離。 那我一定要用兩個相同的子網路嗎? 其實也不一定,如果你今天想比的是一張圖跟一段話之間相不相似,那你當然也可以用一個CNN + 一個LSTM 來當子網路,不過這時候我們就不會叫它孿生神經網路了,而是「偽孿生神經網路」,但基本上就同個概念。 OK,今天這篇就寫到這邊吧~ 感謝觀看,我們下一篇見。
最後附上,文中提及的那兩篇論文。【My Google Drive】
0 評論
發表回覆。 |
Jason Chen人不光是生來就擁有一切,而是靠他從學習中得到的一切來造就自己。- 歌德 文章分類
全部
封存檔
九月 2023
|
