
Ok,首先 Google Colab 這東西 Jason 之前已經有寫過一篇文章來介紹了,如果沒看過的可以參考這個連結: 【開發工具】免費在雲端上玩轉深度學習-Google Colab 至於什麼是 YOLO 再聽我娓娓道來xD 這邊說的 YOLO 可不是你出去玩時會在 IG上 po 照片然後 hashtag 的那個 YOLO(You Only Live Once),而是大神Joseph Redmon 在 2015 年發表的一篇 Paper :You Only Look Once: Unified, Real-Time Object Detection 大神也是把這篇 paper 的名子取的挺逗的,不過你有看過他的CV(見下圖) 的話應該也會覺得這個人超狂的>"< 
痾.. 好像有點跑題了xD
簡而言之: YOLO 就是 Joseph Redmon 等人所提出基於深度學習的 Object Detection 演算法 而 Object Detection ( 物件偵測 ) 也一直是影像辨識領域中非常重要的幾大類任務之一,基本上它就是要負責標註影像中多個物體 ( Multiple Object ) 所在的位置及大小。既然要標註出多個物體所在的位置及大小,那你大概也能想到這樣的話會有兩件事要做,一個就是要找出物件在哪裡,而另一個就是要知道這個物件是什麼,這樣你才有辦法把它框選出來然後標註它嘛~ 然後專業一點來講的話,這兩件事其實就是:Object Localization 和 Classification 既然是兩件事,所以早期在發展的時候我們也都是把它們當作兩件事在處理,像 R-CNN、Fast R-CNN、Faster R-CNN 等演算法都是,而後來漸漸有人想說我能不能把它們合併當作一件事在處理,用一個 model 就把這個問題給解決掉,於是就開始有了些 One Stage Object Detection 的研究,代表的演算法有:SSD 與本文要介紹的 YOLO,而那些分兩階段處理的演算法也就是所謂的 Two Stage。 至於 YOLO 演算法詳細是如何運作、背後的原理等等本文就不會著墨太多,日後有時間再來寫個好幾篇文章詳談,今天就先著重在實作吧!畢竟文章的標題都寫說「在 Google Colab 上創建 YOLOv4 的運行環境」了,再不開始實作就要被噓爆惹八xD Ok,那就先閒聊到這邊,來開始實作吧: 一、在個人的 Google Drive 上新增一個資料夾 ( 非必要 )
【後續相關的資料都會在這個資料夾裡面做同步】
這一步就看個人習慣了,不一定要做,我這邊把該資料夾的名稱取作 "space_for_YOLO"。 
二、進入該資料夾後新增一個 Colab 文件
或者你也可以直接複製一份我的 Colab notebook,這樣你連一行程式碼都不需要打了。
hum... 不過這樣你後面大概也不用看了,你複製回去按個 Run all 就一鍵搞定了xD 連結:https://reurl.cc/KMV24q 
三、開啟 Google Colab 然後啟用免費的GPU
這一步驟的操作 Jason 之前在【開發工具】免費在雲端上玩轉深度學習-Google Colab 就有教過了,如果不知道怎麼操作的可以去參考那一篇,這邊就不重複教了。
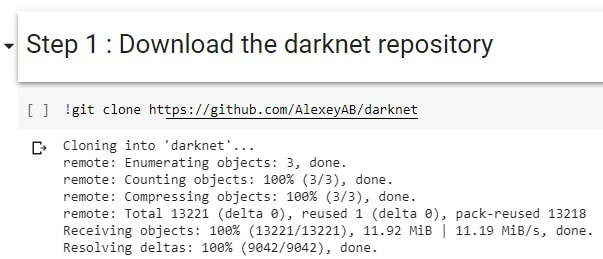
接下來是時候表演真正的技術了,首先我們先 Copy 一份 darknet 的 reop 到你的VM:
下載完成後,我們需要修改 Makefile 裡面的四個參數,分別是:
GPU=0 要改成 GPU=1 OPENCV=0 要改成 OPENCV=1 CUDNN=0 要改成 CUDNN=1 CUDNN_HALF=0 要改成 CUDNN_HALF=1 我們可以透過以下代碼實現: 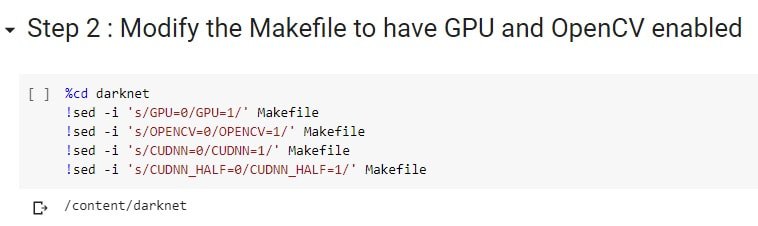
Makefile 修改完成後,我們就 make 指令來生成 darknet 這個深度學習引擎了。

在 make 完成後,其實 darknet 這套深度學習引擎就已經安裝完畢了,接下來我們會想要測試他是否能正常work,所以這時候我們就先去下載一些已經預先 train 好的 weights 檔做為測試用。
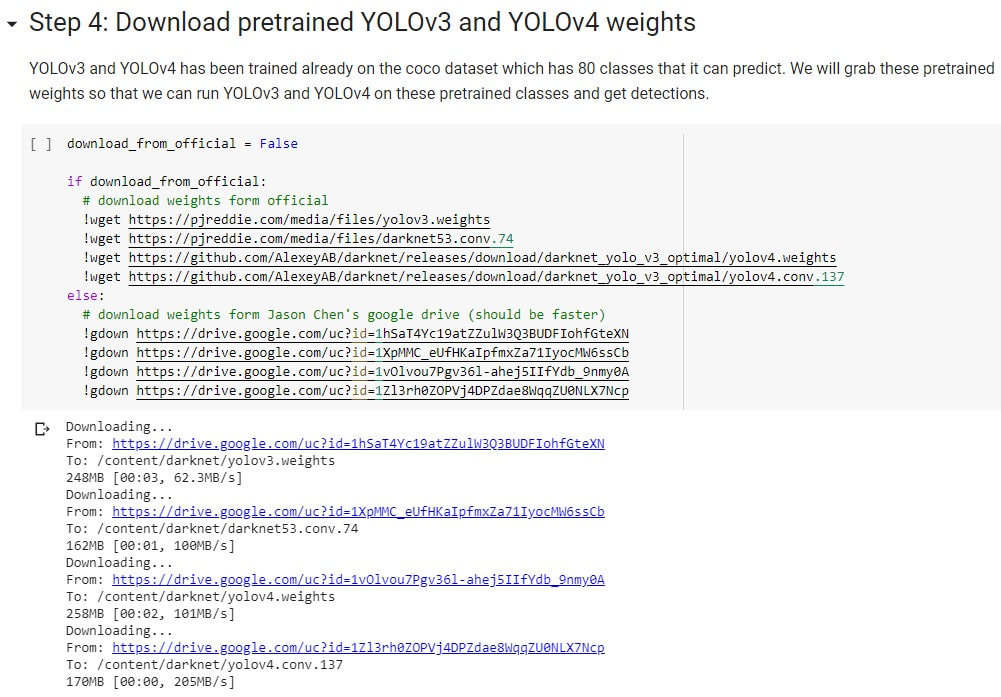
在 weights 下載好之後,我們就可以使用:
!./darknet detect <path of cfg file> <path of weights file> <path of picture> 這個指令進行預測,預測的結果會以 "predictions.jpg" 存在跟 darknet 同一個目錄底下,為了可以直接 show 在 notebook 上面,我們可以多寫一個 imShow 的 function 來實現。 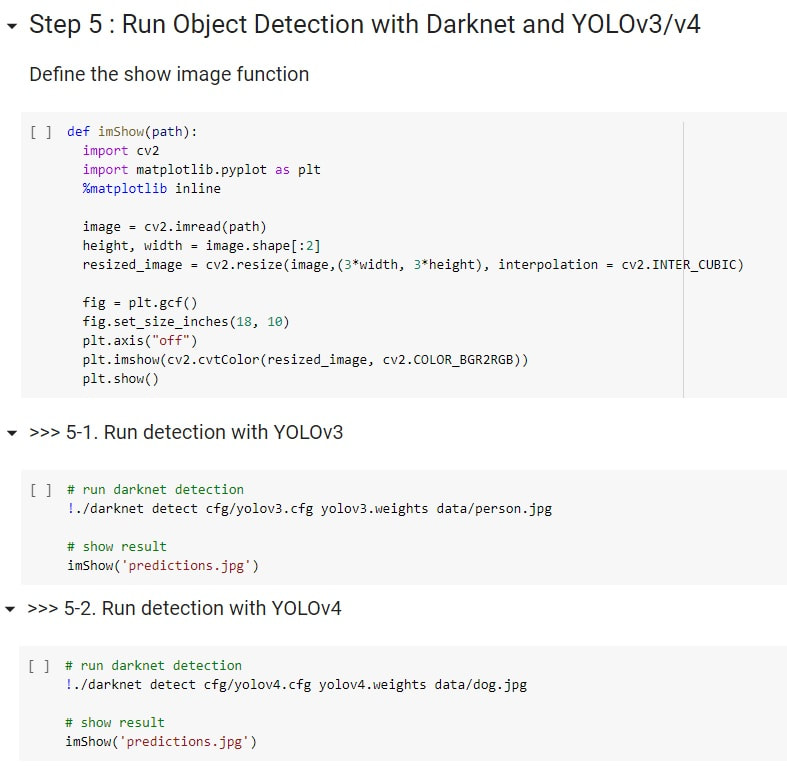
如果你的 darknet 能夠正常 work 的話,你應該能夠看到下方這兩張圖的預測結果。
基本上到這一步你已經在Google Colab 的 VM 上安裝好 darknet 這個深度學習引擎,並擁有一個可以順利運行 YOLO 的環境了!但是為了省去以後每次要在 Google Colab 上運行 YOLO 就要重複上面一系列操作來建環境的麻煩,我們可以把現在建好的這個環境備份到 Google Drive 裡面,以後要用再從 Google Drive 複製回 Google Colab 的 VM 就好了。
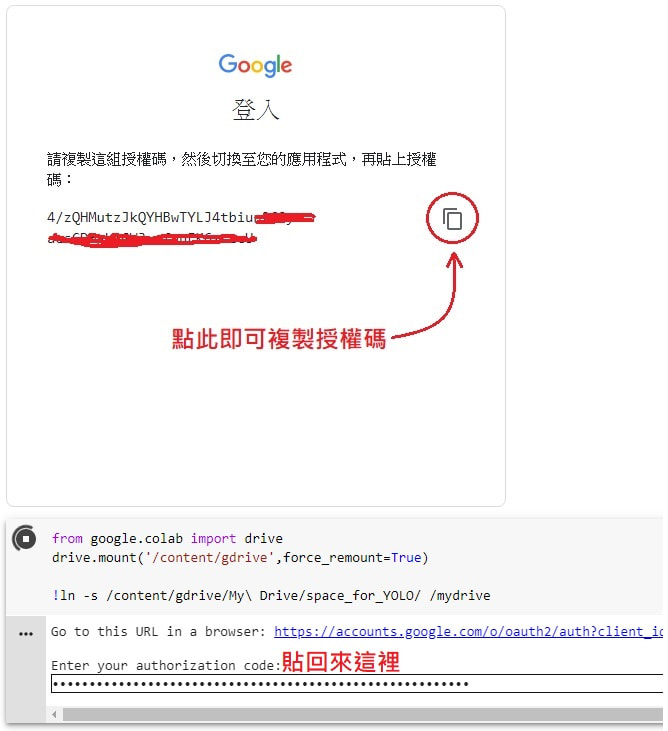
既然要把東西備份到 Google Drive,那麼我們就先把你個 Google Drive 跟 Google Colab VM mount 在一起,此時會需要你點擊它吐給你的連結,然後會跳出 Google File Stream 授權的畫面,你需要同意授權,然後將授權碼複製以後貼回來給它。 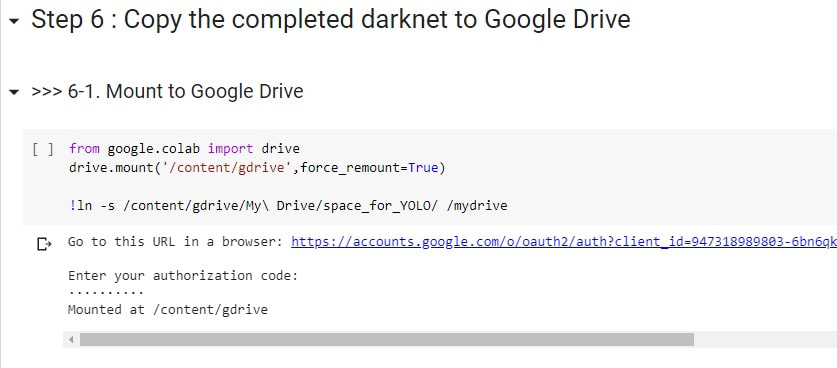
在把 Google Drive 與 Google Colab VM mount 在一起後,我們就可以準備將 darknet 備份到你的 google drive 了,為了節省傳輸的時間我們可以先把整個 darknet 資料夾壓縮起來,在壓縮完成後就可用 cp 指令把它複製進 goole drive 搂~
這樣子就完成摟~ 以後要用的話一樣先把 google drive 與 google colab VM mount 在一起,然後再把 darknet.zip 從google drive 複製回 google colab VM 再解壓縮就好了! Ok,那今天這邊就先寫到這邊吧! 下一篇再繼續講,如何在 Google Colab 上使用 YOLOv4 與免費的 GPU 來 Train 自己專屬的 Object Detector。
5 評論
Cloud
6/16/2023 13:35:36
請問要如何輸出預測目標的位置座標(我想將預測目標的圖框擷取下來)
Jason Chen
6/16/2023 14:37:08
Hi Cloud,
Jason Chen
6/16/2023 14:55:19
如果您並不是要做開發,只是單純的想 "看到" 被框選出來物件的座標的話,你可以在原本測試指令的最後加上 -ext_output,這樣被檢測到物件的座標位置就會直接被印在 comand line 上面了,如果以 repo 中 dog.jpg 為例,用 yolov4 做 inference 的話應該會印出 :
Cloud
6/19/2023 15:06:06
Hi Jason,
Jason Chen
6/19/2023 16:14:03
Hi Cloud, 發表回覆。 |
Jason Chen人不光是生來就擁有一切,而是靠他從學習中得到的一切來造就自己。- 歌德 文章分類
全部
封存檔
九月 2023
|


