今天就來聊聊一般在面試:機器學習工程師、深度學習工程師、人工智慧演算法工程師、大數據分析工程師 等職務的時候,幾乎必問的經典面試考題 - Bias-Variance Tradeoff。 那麼首先就要了解一下: 什麼是偏差(Bias)? 什麼是方差(Variance)?
其實可以套到生活中 "準" 跟 "確" 這兩個概念,如果用高中軍訓課打靶的經驗來說,那就是:
如果說你打靶打得很精 "準",意味你子彈射中的地方離靶心很近,即 Low Bias; 如果說你打靶打得很精 "確",意味你在發射數槍之後這幾槍彼此之間在靶上的距離很近,即 Low Variance。 接著下面用一張圖來說明,應該就一目了然了! 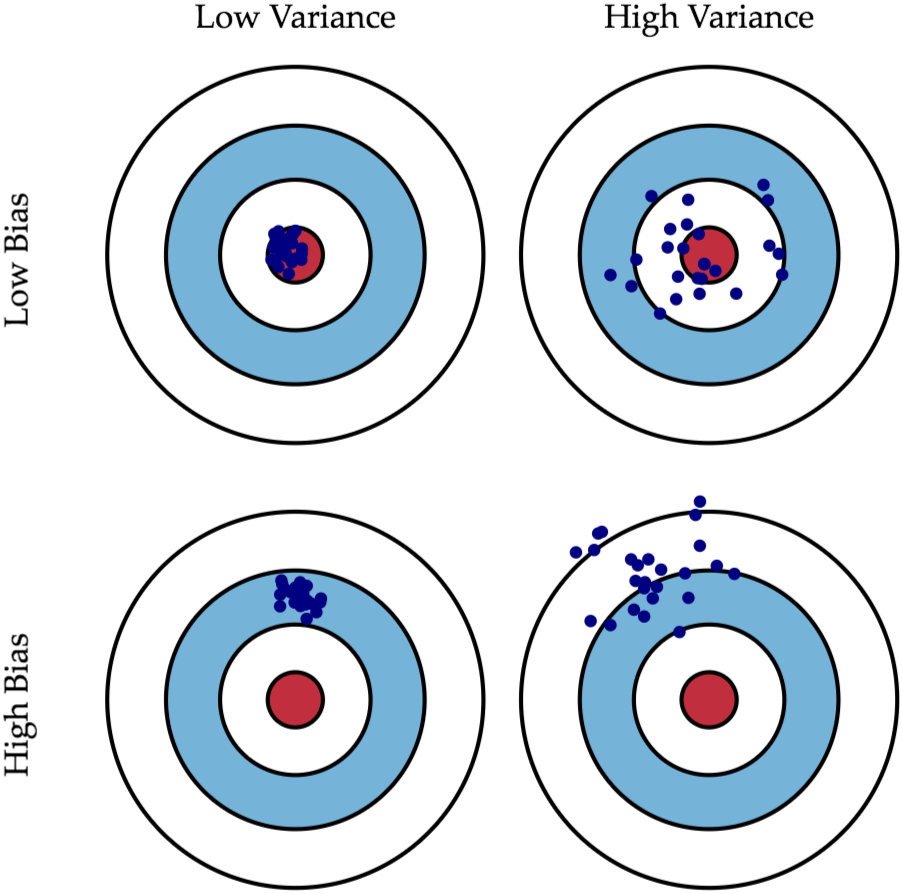
而在機器學習領域我們都希望能夠把 Model 訓練到非常的 "準確" ,即你的模型是可以用來描述數據背後的真實規律、真實意義,以便後續我們用這個模型來執行一些描述性的任務或預測性的任務。 BUT!人生最討厭的就是這個BUT! 真實的世界並沒有這個美好,一般我們在實作上會碰到的誤差有:隨機誤差、偏差、方差,其中隨機誤差的部分源於數據本身,基本上沒有辦法消除,而偏差與方差的部分又跟 Overfitting & Underfitting 的問題緊緊綁在一起,所以才造就了今天的這篇主題:Bias-Variance Tradeoff,顧名思義,就是我們希望透過權衡 Bias Error 跟 Variance Error 來使得總誤差( Total Error ) 達到最小。 那麼想把總誤差降到最低,不就想方設法把 Bias Error 跟 Variance Error 都降到最低就好了嗎? 換言之,也就是達到上圖左上(Low Bias & Low Variance) 的樣子。沒錯,理論上是個樣子,如果你今天有無窮的數據 + 完美的算法模型 + 不可思議的運算能力,理論上是有辦法辦到的!然而在現實生活中,我們要用來解決一些實際的工程問題時你就會發現,你的數據跟計算能力都是有限的,算法模型也不會是完美的。 我們舉個例子來看吧,假設我們今天拿到一筆資料的分布如下: 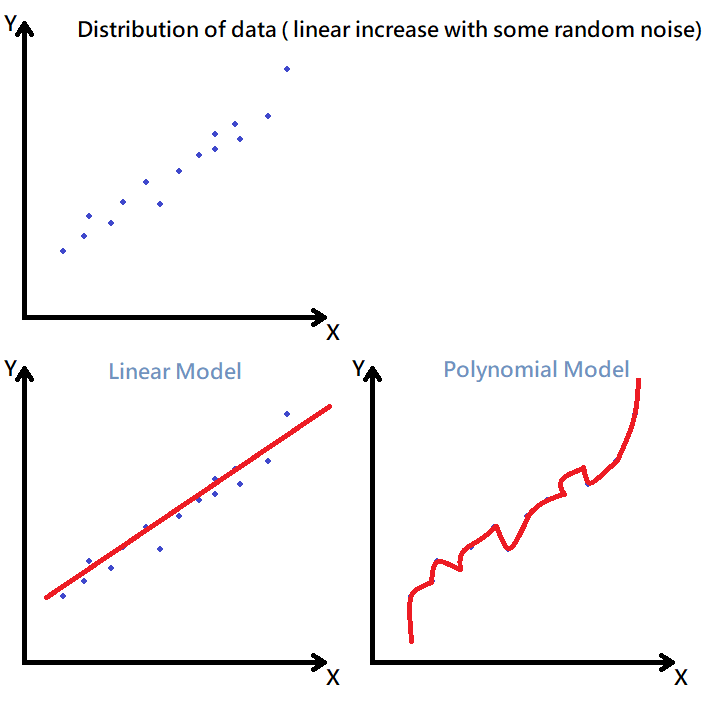
如果是人的話,大概可以很直觀的看出資料似乎呈現某一種線性分布,不過帶有一些隨機擾動的成分在裡面。這時候如果你讓電腦用一個非常簡單的線性數學模型 e.g.
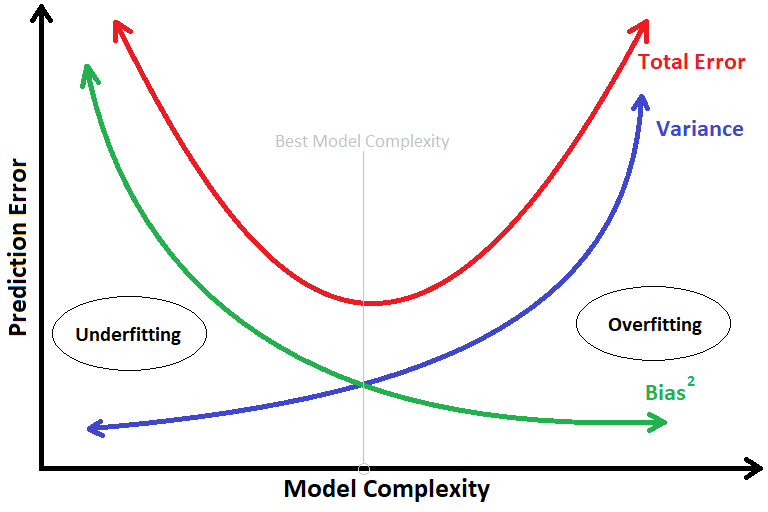
y = mx + b 盡可能地去近似 ( 擬合 ) 這些資料的時候,你會發現它的偏差是比一個複雜的多項式模型高很多的。像我們在高中的數學中就有學過,如果在一個平面座標系上有N個點,你是可以用一個N次多項式來完美通過每一個點。 y = a0 + a1x +a2x^2 +a3x^3 + ... +anx^n 於是你畫了一條奇形怪狀的線來通過每一個點,然後你發現這樣的模型算起來偏差可就降到 0了呢! 哇~ 偏差降到 0了,聽起來好像還不錯啊~ 先別高興得太早,因為我們最終的目的是希望拿這一個模型對以後一些未知的資料來做預測。所以我們就拿一筆全新的資料 ( 即不存在訓練集當中,模型之前完全沒看過的資料 ) 要給模型來做預測,你就會發現用N次多項式模型所做出來的預測,答案錯的有夠離譜,反而線性模型做出來的預測會比較接近真實答案。 原來就是因為,一開始你太過希望能把偏差降到 0,所以建了一個非常複雜的模型,讓你的模型可以死記硬背的將所有訓練集中的資料都硬背下來,這麼做有一個明顯的問題就是,你的資料裡面是帶有很多隨機誤差,你又把這些隨機誤差都全部擬合進模型裡面,會容易導致你的模型失去了泛化的能力,對於這樣的結果一般我們也稱作 Overfitting,指你的模型過度擬合了。 模型一旦 Overfitting 以後,對於未知的資料預測的能力就會很差,也就造就了很高的 Variance Error。 如果我們將 模型的複雜度 與 模型預測的誤差 畫成圖表的話,見下圖: 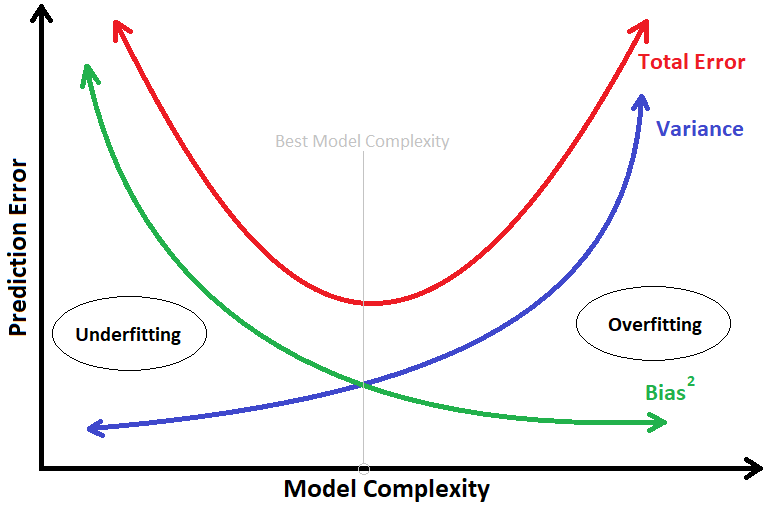
你就可以發現,隨著模型複雜度的增加偏差會越來越低;而方差卻呈現了越來越高的趨勢,兩者是呈現 Tradeoff 的,只有在模型複雜度適中的時候,才有辦法得到最低的總誤差!
Ok, 那可能有人會想說,既然如此,能得到最佳總誤差的點會落在 Total Error 函數的轉折點,而 Total Error 又是從 Bias 跟 Variance 而來,Somehow 我應該能寫出一個數學式子來找出那個最佳模型複雜度是多少吧! 理論上是這麼說沒錯,不過在實務上有時候我們可能會很難去計算模型的偏差與方差。 所以在實務上我們更常透過模型外在的表現來判斷它現在是 underfitting 還是 overfitting,再透過調整模型的超參數( Hyperparameter ) 來調整模型的複雜度。實際操作上,一般我們會將 dataset 切割成 training set 跟 validation set,training set 用於訓練模型;而 validation set 將不會參與訓練,用於評估模型是否 overfitting。 如果這部分一樣把 模型的複雜度 與 模型預測的誤差 畫成圖表的話,見下圖: 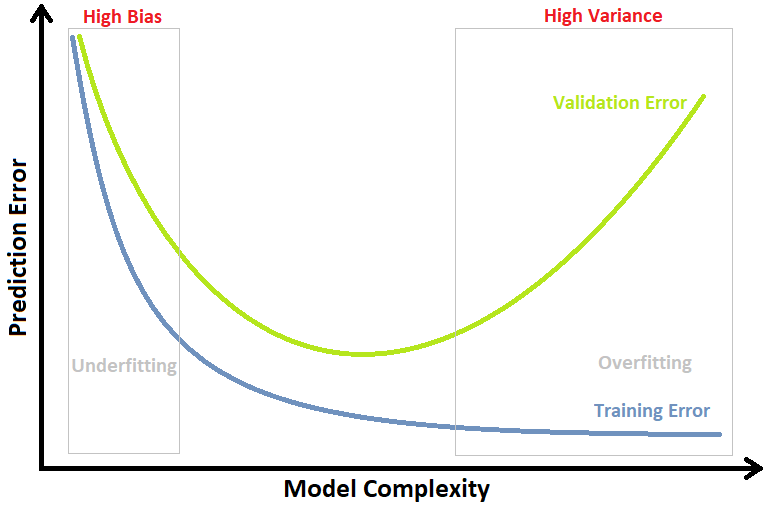
可以觀察到:
Overfitting 與 Underfitting 的應對之道
我們在訓練一個 ML model 的時候,Overfitting 與 Underfitting 是一個非常實際的問題,也非常容易發生,所以也就有一招又一招的解決辦法。
【Underfitting】
【Overfitting】
Ok, 那我想這篇就寫到這邊吧!
0 評論
發表回覆。 |
Jason Chen人不光是生來就擁有一切,而是靠他從學習中得到的一切來造就自己。- 歌德 文章分類
全部
封存檔
九月 2023
|
