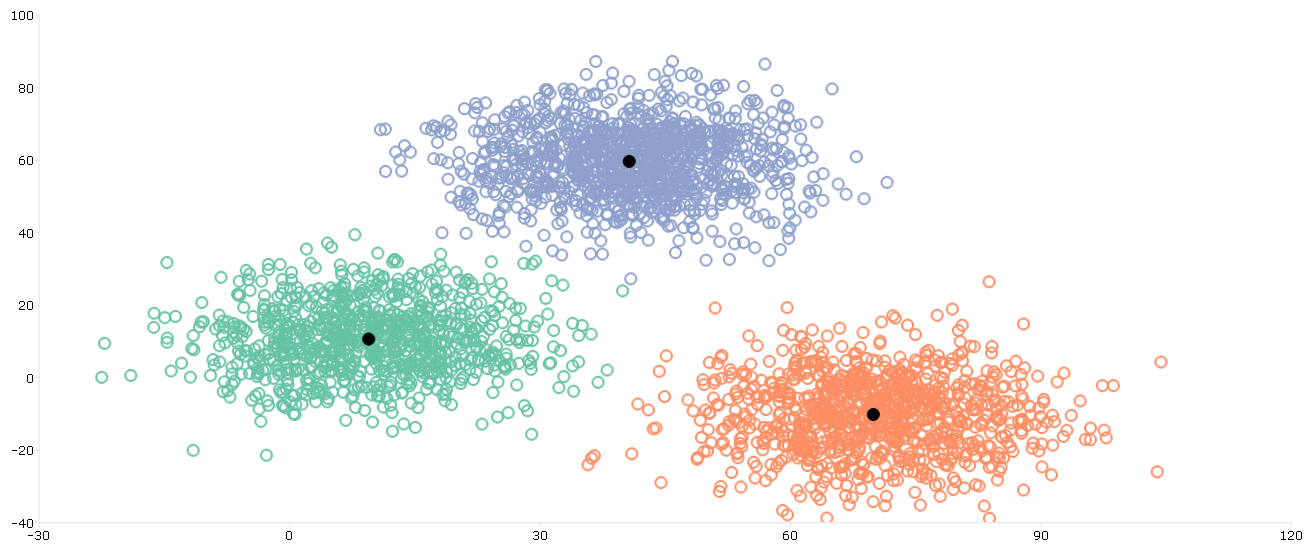
K-means Clustering,顧名思義它是一種 Clustering Algorithm。Clustering 的中文可以翻作分群、集群或聚類。對於剛接觸機器學習的人,常常因為分群跟分類這兩個名詞在中文字面上看起來很相像,而對這兩個觀念有一點混淆。事實上它們是兩類不同的演算法,所以為了避免混淆,我習慣把 Clustering 稱作聚類,這樣在提到分類與聚類的時候,我們就能更直觀的理解它們是兩類不同的演算法。 基本上 Clustering Algorithm 都是在做非監督式學習 ( Unsupervised Learning ),而今天要介紹的K-means 也不例外。所謂的監督式學習與非監督式學習,它們的差別就在於資料集本身,監督式學習使用的資料集裡面除了資料本身之外,還帶有一個 Ground Truth 的正確解答;而非監督式學習使用的資料集裡面就只有資料本身。 舉個例子來說,這是一般監督式學習使用的資料集: 
你可以看到,除了資料本身 ( .png 圖檔 ),我們還會有 Ground Truth 的正確解答 ( 圖片裡面的英數字是多少 )。但在現實生活當中,很多問題我們往往只有辦法收集到資料,沒有辦法伴隨取得正確解答,所以這時候我們就沒又辦法來使用那些監督式學習的方法,必須轉而使用一些非監督式學習的方法。
我們把它換成一個簡單一點的問題,比如說我們想基於一個人的身高體重來預測他/她的性別,然後我們收集到一群人的身高體重,但是在記錄的時候卻沒有記錄到性別,假設資料長得像這樣:
可以看到裡面就只有身高跟體重的資料,我們並不知道該筆資料是屬於男性的還是女性的。
就像上面說的,既然沒有正確解答就沒有辦法用監督式學習的方法來做,於是我們就想用非監督是學習 - 聚類的方法來解解看。 而 Clustering 說穿了,就是一個「物以類聚」的概念。 我們的目的是希望讓男生的資料可以自己變成一群,女生的資料自己變成另一群。理論上同一群的資料應該會具有某依些相似的特徵,所謂的"相似"在數學上就是距離比較近 ( e.g. 1、2、97、99,1跟2就相似,97跟99比較相似。) 如果我們將上表的資料對應到一個二維的特徵空間來看的話: 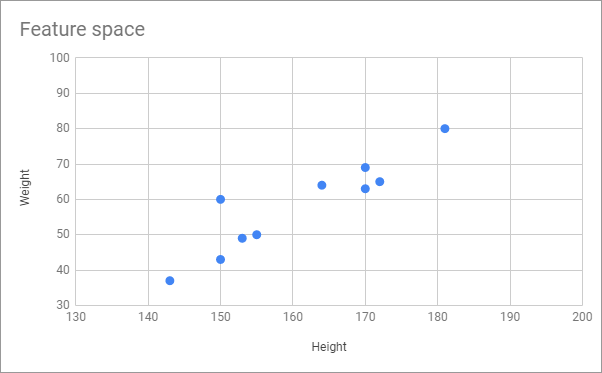
當然像這樣簡單的資料,由我們人來看的話大概也能很輕鬆的將其分成兩群:
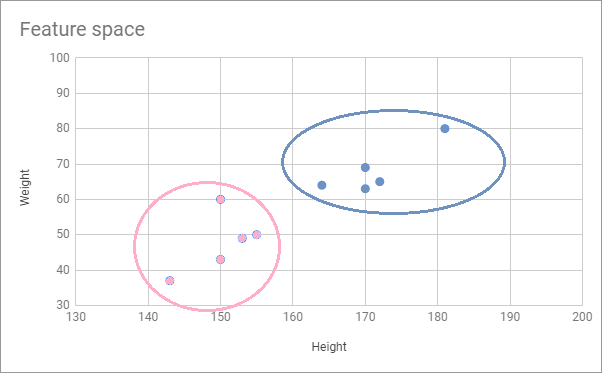
而電腦要做到這件事,就是利用聚類的演算法;聚類的演算法有很多,最經典的就是接下來要介紹的 K-means。
K-means 運作的流程步驟:
Jason 用上面的例子幫大家做了張 Gif 以便可以更好的了解這個演算法的運作流程: 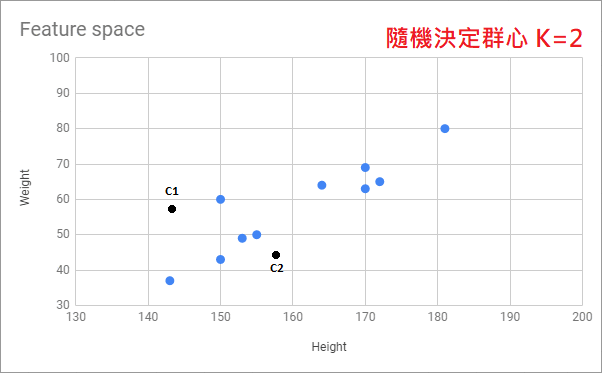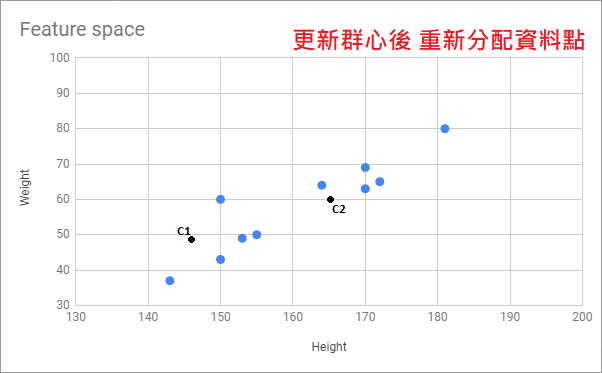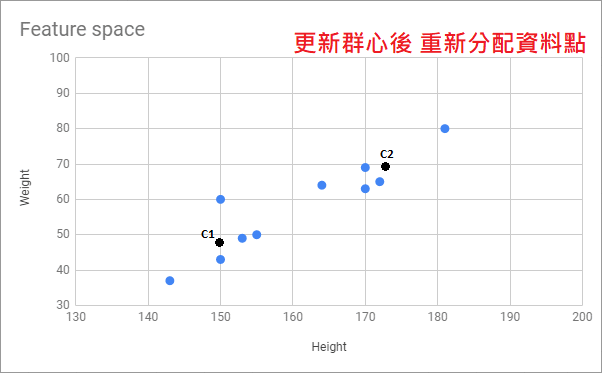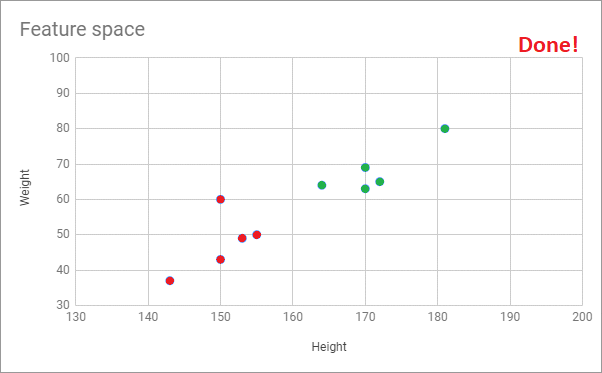
K-means 演算法的時間複雜度為 O(NKT) , 其中:N 為資料的數量, K 為群集數量, T 是重複次數。
不過由於我們無法預先得知,在演算法執行的過程中會重複幾次 ( 取決於數據分布的情況、群心的初始位置等 ) 所以時間複雜度啥的我覺得參考就好 ( 即使同一批數據跑 K-means 每次收斂的時間都會不太一樣 )。 這時候你大概也可以感覺得出來,如果一樣是要做分類問題,用非監督式學習的效果基本上會比同類型的監督式學習來的差,因為模型在訓練的時候你沒有標準答案,它只能自己從資料本身去找關係,所以在遇到一些 Misclassification 資料的時候分類效果就不會太好。 話雖如此,但 K-means 絕對排的上最經典的十大機器學習算法之一,每個搞 Data Mining、Machine Learning 的人都必須要會的!在面試 AI、Big Data 相關職位的時候也是常常會考的題目之一。 最後在附上使用 Python 實現 K-means 的代碼給有需要的人參考。 【下載程式碼】
0 評論
發表回覆。 |
Jason Chen人不光是生來就擁有一切,而是靠他從學習中得到的一切來造就自己。- 歌德 文章分類
全部
封存檔
九月 2023
|
