
「對抗樣本 Adversarial Examples」是機器學習裡面非常有趣的一個現象,基本上是說當你在正常樣本中添加一個特定的雜訊進去之後,就可以讓你的模型整個ㄎ一ㄤ掉、產生幻覺,就像本篇封面所展示的這樣,原本一張好好的 panda照片在加入圖中的雜訊後,在人眼看來它明明就還是 panda,但是你的 model 就覺得 no no no 它是 gibbon(長臂猿)喔。 而這 AI model 還不是什麼隨隨便便的兩光AI,基本上都是動用了數萬張GPU 訓練了數萬個小時,公認在影像分類(Image Classification)任務上非常強健(robust)的模型。只不過我們添加進去的雜訊也明顯是個狠角色,自然不是什麼隨機生成的產物,而都是被人精心設計過專門用來攻擊這個 AI model 的。 雖然我們的人腦也不太可靠,也是有一堆視覺上的錯覺、幻覺,像是著名的棋盤陰影錯覺、黑森錯覺等等。但至少這些錯覺並不會影響我們平常生活、工作與任務的執行,而對抗樣本在AI 中卻會導致災難性的結果,舉例來說,今天如果你用對抗樣本來攻擊自駕車的AI,就可以讓它把紅燈判斷成綠燈,或者讓路上的行人在AI的眼中隱形。 
人腦為什麼會產生錯覺我不知道,但是 AI 的底層就是純數學啊~ 怎麼也會產生錯覺?貌似很不應該,所以很多人覺得所謂的對抗樣本就只是 AI 的 Bug,一個尚未被我們攻克、解決的問題。但是如果我們回歸到原理的層面來看,我們的模型是基於決策函數(Decision Function),或者在高維空間中會稱作決策邊界(Decision Boundary) 來進型分類的,而你每個類別在高維特徵空間中被決策邊界包起來的區域,應該會長的蠻奇形怪狀的、又彼此緊緊相鄰,甚至某一個類別在某一個維度的決策邊界特別特別的窄,隨便加一點雜訊上去就會跑到隔壁類別去那種。 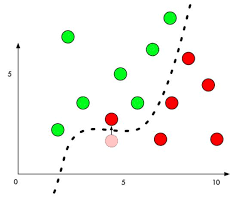
而模型的決策邊界又完全是基於數據學習而來,今天除非你有無窮無盡的數據可以讓你的模型來進行學習,不然難免會遇到維度詛咒(Curse of Dimensionality)的問題,所以說截至目前為止,對於Adversarial Examples 科學家們仍然沒有什麼好的解決辦法。 雖然問題還沒解決,但錢還是要賺的! 如果公司企業沒有辦法從 "AI" 這東西中獲利的話,好不容易復燃的星星之火等等就又熄滅了吧~ 既然是種攻擊,那自然也會有一些應對(防禦)的方法,像是在訓練模型的過程中就自行加入對抗樣本(稱作:對抗性訓練),或者使用防禦性精煉的策略等等。 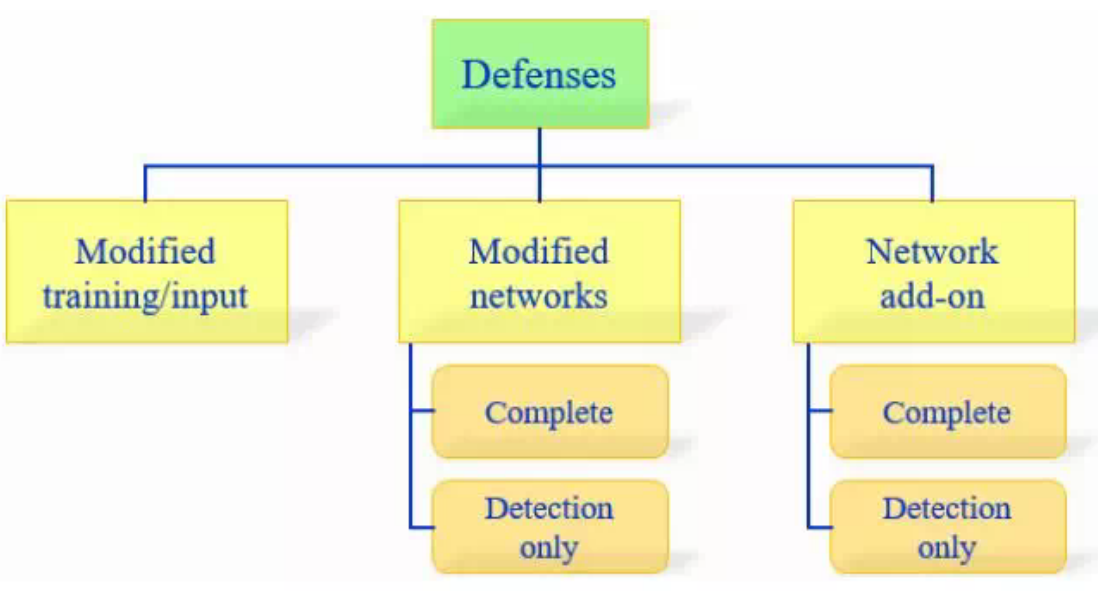
但最終在這場對抗樣本的攻防戰中,防守方可以說是敗的一踏塗地,特別是在白箱攻擊上(一般而言,我們可以將攻擊的種類分成:黑箱、白箱、無箱)。其實目前 AI 的發展跟早期電腦、網路以及其他資訊系統的發展都差不多,電腦也是先被開發設計出來,然後遇上史上第一個電腦病毒,在被搞得生活無法自理後,才有了防毒軟體,時至今日防毒軟體與電腦病毒的抗爭也從為停息過。而 AI 與 對抗樣本的問題也亦同吧~ 最後附上一些對抗樣本相關的論文:https://reurl.cc/jlb6Wn
0 評論
發表回覆。 |
Jason Chen人不光是生來就擁有一切,而是靠他從學習中得到的一切來造就自己。- 歌德 文章分類
全部
封存檔
九月 2023
|
