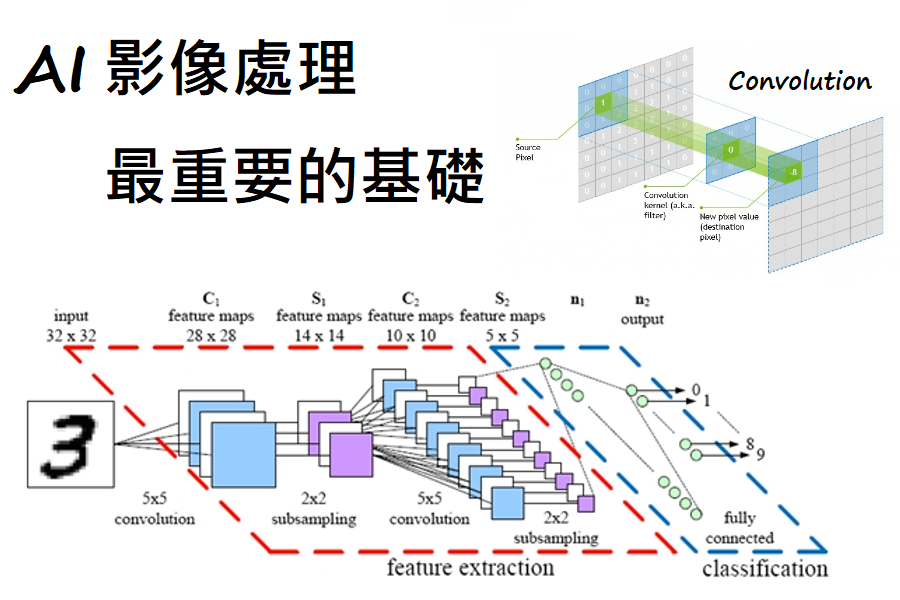
都拖到 2021 了 Jason 才寫這篇文章,不知道會不會給人一種野人獻曝的感覺xD 不過會突然想回頭補這篇文章也是出於無奈啊~ 由於最近 Transformer-Based Model 正在勢頭上,在各大領域大放異彩、達到 SOTA(State-of-the-Art),不禁讓人讚嘆 果然 "Attention Is All You Need" 之外,就想到如果這篇文章再不寫的話,以後可能也不用寫了 Orz 言歸正傳,說到現在 AI 深度學習在電腦視覺 CV 領域的應用,不論是經典的影像分類網路e.g. LeNet、VGG、ResNet、etc,或者物件偵測網路e.g. R-CNN、YOLO、SSD、etc,基本上它們都有一個最核心、最重要的共同基礎那就是:卷積核 Convolutional Kernel,而這些基於卷積核設計的網路,都可以通稱為 CNN-Based Model。 所以問題來了,卷積核是幹什麼用的? 為什麼它在電腦視覺領域中就那麼重要呢? 其實卷積 Convolution 也不是什麼新東西、新技術! 它就是我們在數學裡講的那個卷積! 有點忘了它在不在高中數學的範疇裡面,但蠻肯定大學時期的微積分、工程數學會學到。 而它在我們傳統的訊號處理、影像處理中更是有大量的應用,比如說我們利用下面這一組卷積核來對某張影像作卷積運算,就能得到下圖的結果: 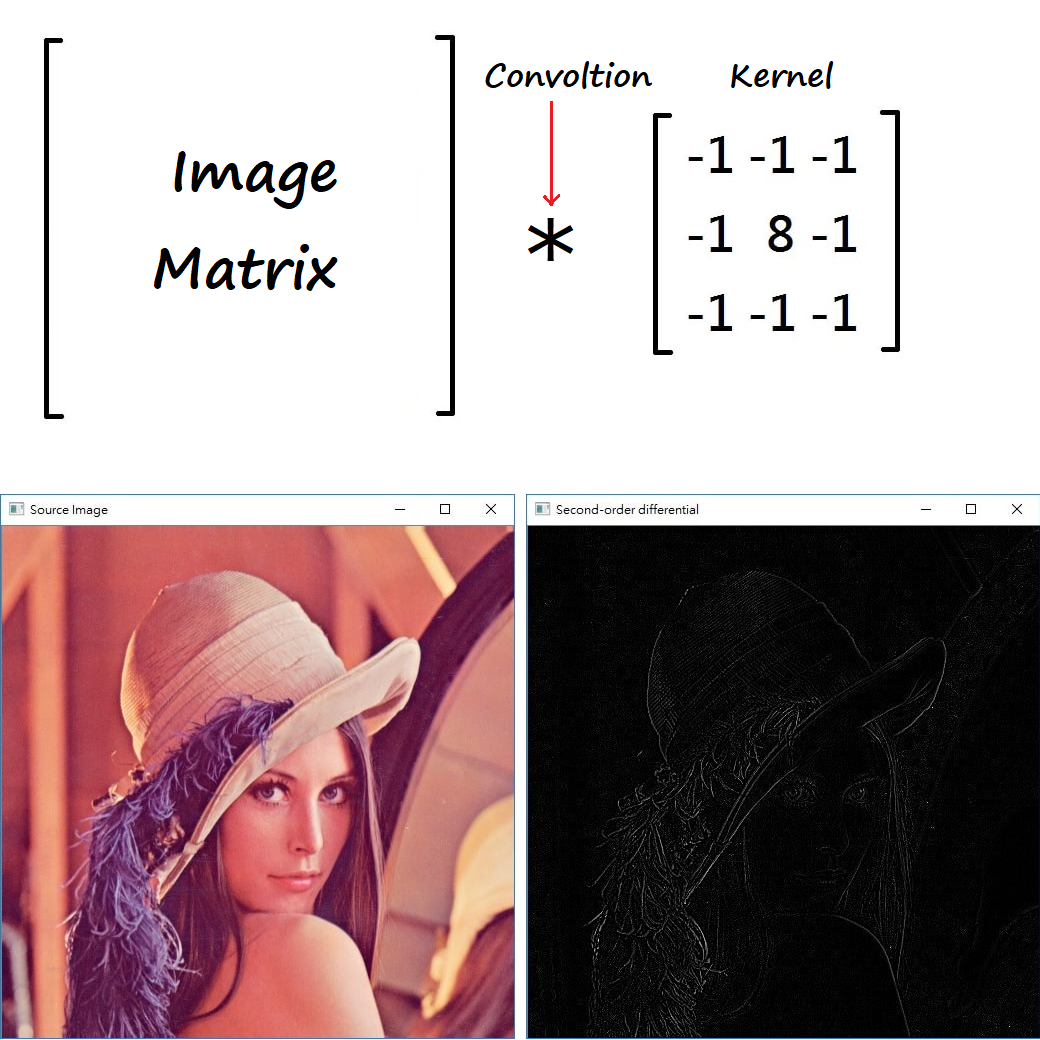
左邊是原圖,右邊則是對原圖用該卷積核做完卷積後的結果。 可以看到影像中大部分的東西都被濾掉了(數值變成0 顯示上則成黑色),只剩下原本影像中物體邊緣位置的資訊。其實這就是一個卷積在影像處理中很經典的應用之一,邊緣偵測(Edge Detection)。也因為做完卷積後可以濾除掉很多不必要的資訊、只留下我們感興趣資訊的這個特性,所以在傳統的影像處理中,捲積運算的捲積核Convolution Kernel 也被稱作 Mask 或 Filter,其他關於捲積在影像處理中更 detail 的內容我就不贅述了,感興趣的可以參考 Jason 我之前寫的【影像處理系列文章】。 怕各位貴人們多忘事,以前學的數學已經還給教授or數學老師了,Jason 這邊就稍微幫大家複習一點數學,解釋一下什麼是到底什麼是捲積運算。不過說到底也是蠻簡單的啦~ 基本上就是相乘之後再相加,見下圖: 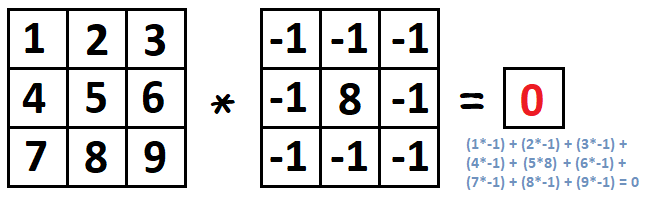
看到這邊可能有人會想說,我在上圖展示的是 Input Image ( Matrix ) 的尺寸大小剛好與捲積核的尺寸大小一致時做捲積運算的結果,但現實中我們的 Input Image 往往是比捲積核大的多的,那這時候又該怎麼做計算呢? 其實這也還好,萬變不離其宗,我們一樣是在做捲積運算,只是再幫它套上個 Sliding Window 讓它一格一格慢慢滑過整張影像,以此來對整張影像做運算。
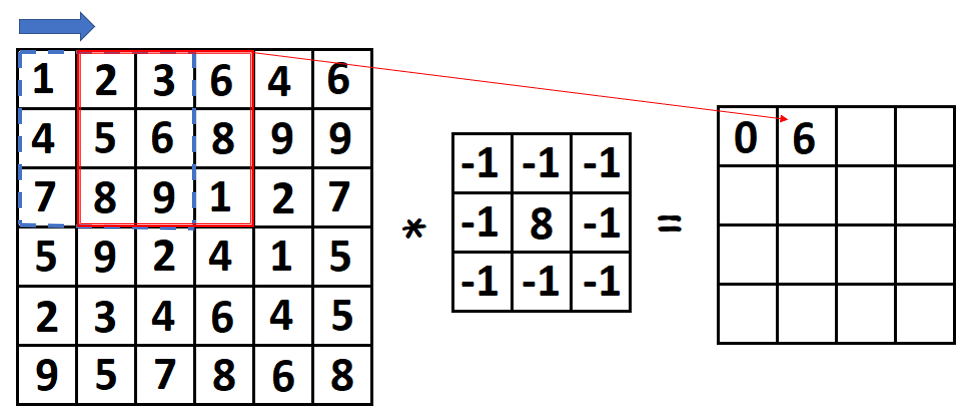
看到這邊你可能會有個感覺就是:好像只要把影像套某個捲積核做捲積運算之後,就可以把影像中的背景給濾除掉,只留下我們感興趣的影像特徵。那我只能說,你的思路對了!這也是捲積運算在傳統影像處理最重要的應用之一,但就變成說要怎麼去設計這個捲積核是一門很大的學問,在以前學影像處理的時候,我們甚至要將影像用傅立葉轉換將影像變到頻域作分析,在頻域設計好一個濾波器後再用反傅立葉變換把它變回空間域的捲積核來用,ㄜ.. 好像有一點跑題了xD
讓我們回到 "感覺" 上,捲積運算的相乘再相加,484讓你想到了什麼? 沒錯!! 我們最基本的 ANN ( Artificial Neural Network ) 的數學運算不就也是先相乘再相加嗎? 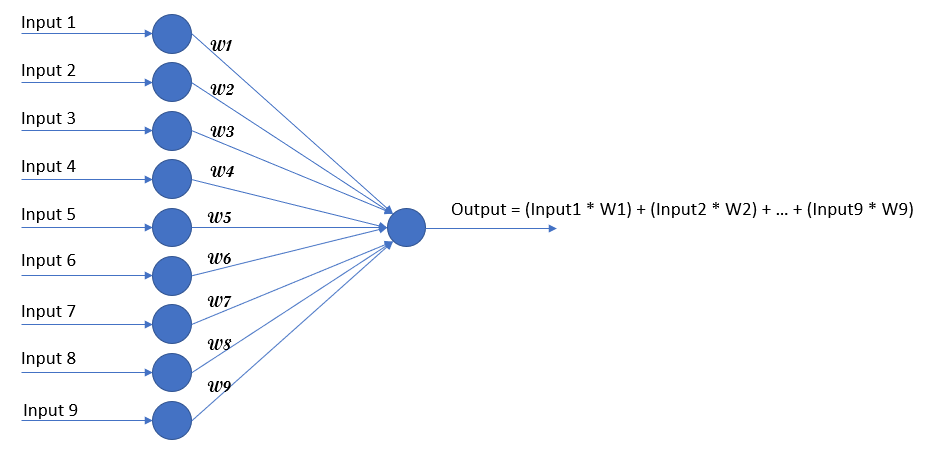
只是差在說原本 ANN的架構,它在處理影像資料時是把影像攤平成一維輸入的資料,並將影像中的每一個像素點(pixel)都連接到下一個 Layer 的每個 Neural 上(即 fully connected 架構)。這樣的架構在影像大小 3*3 時跟使用 CNN 是沒有本質上的區別的,但如果今天輸入的影像大小為 1920*1080 呢?
兩者之間就發生了質的改變,ANN 架構的會變得異常的肥大,這會導致模型非常難 training、很難收斂,而CNN則很巧妙的利用了影像本身的特性:
於是 CNN 就利用這一個特點開發出它另一個強大的武器:Pool Layer 常見的有:Max-Pooling、Mean-Pooling、Min-Pooling,一般我們是傾向使用 Max-Pooling 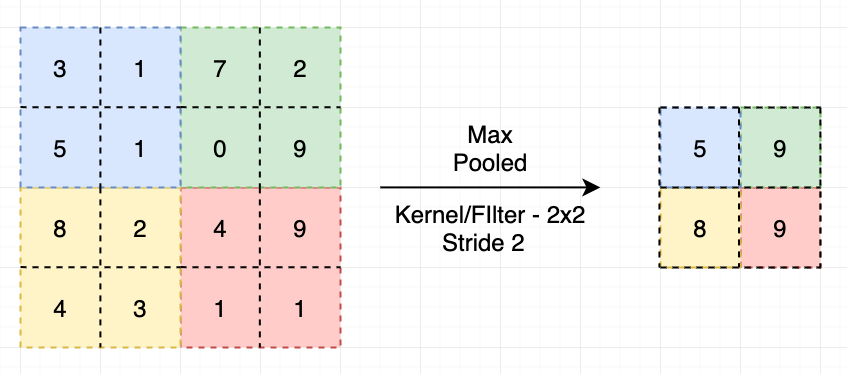
Max-Pooling 的概念也是蠻簡單的,就是用那個區塊裡面的最大值來代表那個區塊。
在影像中實作的效果如下圖所示: 
在上圖中可以看到,在經過 Max-Pooling 以後,影像中較強、較重要的資訊有被保留了下來,整體影像的語意也沒有發生改變,並且能使整個影像的大小縮減了 3/4 ( 長寬減半;面積減少3/4 ),而把 Max-Pooling 的技巧應用在 Feature map 上時也是有類似的效果。於是 CNN 就能巧妙的利用了這套組合拳,利用卷積核省掉了不必要的連接,並實現了 "權值共享" ,加上每次卷積後再採用一層 Pool Layer,萃取卷積找到的特徵,直到模型的輸出層為止,每一層都越捲越小,進而大幅度的縮減了整個神經網路的尺寸大小。
所以一般 CNN 都是被我們當成影像的特徵提取器來使用,在模型的前面先使用 CNN 來很好的提取出影像的特徵之後,我們只要在網路的後面再加上一般的DNN,就可以很容易用來實現一些分類、回歸、物件偵測等等之類的任務了。 Ok,關於 CNN 最重要的那些觀念都講完了,這篇也可以功成身退了! 那我們就下一篇再見 881~
0 評論
發表回覆。 |
Jason Chen人不光是生來就擁有一切,而是靠他從學習中得到的一切來造就自己。- 歌德 文章分類
全部
封存檔
九月 2023
|
