CAPTCHA 的全文是「Completely Automated Public Turing test to tell Computers and Humans Apart」,字面上的翻譯是:全自動區分電腦和人類的公開圖靈測試,咋聽之下好像蠻高大上的,不過其實它在我們生活中還蠻常見的,也就是我們俗稱的驗證碼。 
CAPTCHA 主要是一種用來區分 User 是 Bot 還是真人的機制,在 CAPTCHA 的測試中,Server 端會生成一個問題由 User 來解答。這個問題由電腦自動來生成並與評判,而問題必須設計成只有真人才能解答,由於我們把設計成電腦無法解答,所以可以藉由 User 是否能正確的回答問題來判斷是真人還是 Bot。
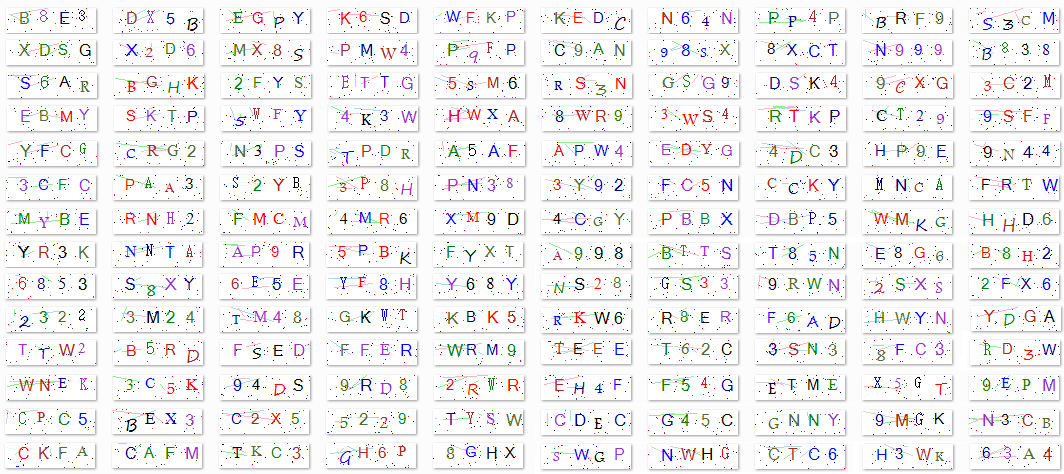
CAPTCHA 當初它被設計出來的目的就是為了抵抗日漸盛行的網路爬蟲(Web Crawler)技術。網路爬蟲也有人叫它網路蜘蛛(Spider),是一種用來自動瀏覽全球資訊網(World Wide Web)的網路機器人,它主要的目的也就是到各個網站去抓資料。雖然有人用程式到你的網站來抓資料聽起還好像沒有很 "母湯" 但是事實上,現今的網站普遍來說或多或少都會配置一些反爬蟲手段,畢竟現在就連一台筆記型電腦的性能可能都比某些小站的伺服器還強,如果它不對此加以限制,分分鐘你伺服器的資源就會被爬蟲給耗盡了,使得無法去服務真實的用戶。 而最終基於上述這個理念所發展出來的 CAPTCHA 機制也是形形色色,早期的 CAPTCHA 主要都是基於圖像的(輸入字符 or 選出飛機、斑馬、大象等等),到後來現今仍蠻常見 Google 的 reCAPTCHA v2(在一個小視窗中勾選我不是機器人),以及最新的 reCAPTCHA v3 等等。 本文接下來要提供的就是早期那種基於圖像要求 User 輸入字符的 CAPTCHA Image ( with Label ) Dataset。 其實這個就是我在【經驗分享】興大資工 碩士在職專班:修課心得 一文中所提及:用來訓練 CNN 去破解年代售票系統 CAPTCHA 的 Dataset,Jason 最近剛好碰到有人跟我要這份資料集,就想說乾脆寫一篇放在網路上公開給大家做使用吧~ 其實這份資料集除了可以用在機器學習、深度學習等領域外,也蠻適合拿去做傳統影像處理 OCR 的研究。 裡面包含了11308 張 內有4個字符的 CAPTCHA 圖檔,解析度為:90*25、保存格式為:png 及一個記錄11308 筆正確解答的CSV檔:label.csv 【檔案下載連結】
3 評論
余佑駿
5/11/2020 17:52:03
下載連結好像不行欸><
Jason Chen
5/11/2020 20:31:43
Hi 余佑駿,
余佑駿
5/12/2020 06:12:59
謝謝!!可以了~ 發表回覆。 |
Jason Chen人不光是生來就擁有一切,而是靠他從學習中得到的一切來造就自己。- 歌德 文章分類
全部
封存檔
九月 2023
|
