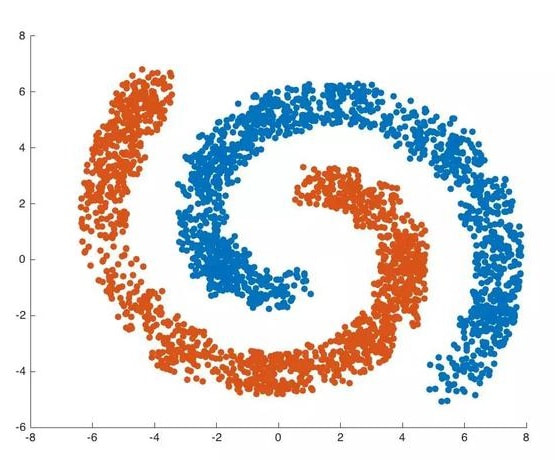
Clustering 聚類演算法,你也可以把它翻作「分群」或者「集群」 演算法,它是一種非監督式學習的演算法。主要的思想是,因為常常我們有的只是資料本身但並沒有該筆資料 Ground Truth 的正確標籤 ( Label ),於是我們希望能有一個演算法能夠讓資料們自己「物以類聚」,有相似特性的資料就自己聚成一類。像 Jason 之前有寫過一篇 【機器學習】聚類分析 K-means Clustering 裡面介紹的就是一個蠻經典的聚類演算法 K-means,而今天要介紹的是另外一個不同的聚類演算法 DBSCAN。 DBSCAN 的英文全寫為 Density-Based Spatial Clustering of Applications with Noise 顧名思義,他是一個基於 "密度" 來進行聚類的演算法,與我們比較熟悉的K-means 那種基於距離的不同。舉個簡單的例子來說好了,下面有兩種不同的資料分佈方式,其中左邊的部分,我們可以用之前提到的 K-means 演算法就可以得到很好的聚類效果,但是在右邊的那種資料分佈上 K-means 就變得不太 Work 了。 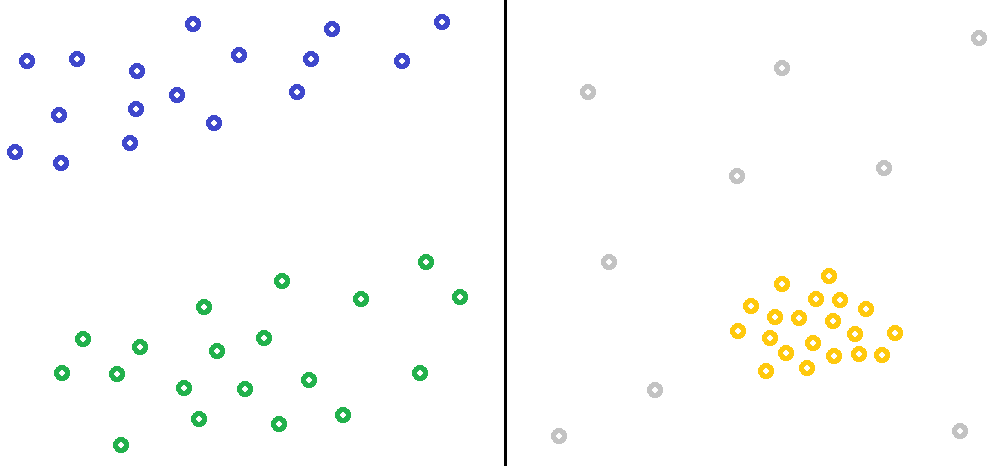
而 DBSCAN 演算法根據資料點在特徵空間中的密度進行聚類,基本的流程是:給定某特徵空間裡的一個資料點集合,演算法會把附近的點分成一組(有很多相鄰點的點),並標記出位於低密度區域的局外點(即最接近它的點也距離非常的遠),也就能把一些離聚集點比較遠的點自動被當做雜訊(noise)或者也可叫作離群點(outliers)給剔除掉。DBSCAN 跟 K-means 一樣,算是蠻常用的聚類分析演算法,在一些論文中也常被引用。 雖然我們人可以很直覺的在二維空間中看出哪些資料點比較密集、哪些又比較稀疏,但是對電腦來說這些點都只是一筆一筆的資料,而它會做的就是利用演算法對這一筆一筆的資料進行運算。接下來我們就來看這個演算法到底怎麼執行! 首先在開始之前我們需要定義兩個參數,分別是:
為了更好理解上面那段文字在講什麼意思,接著我們用下面這一張圖來看: 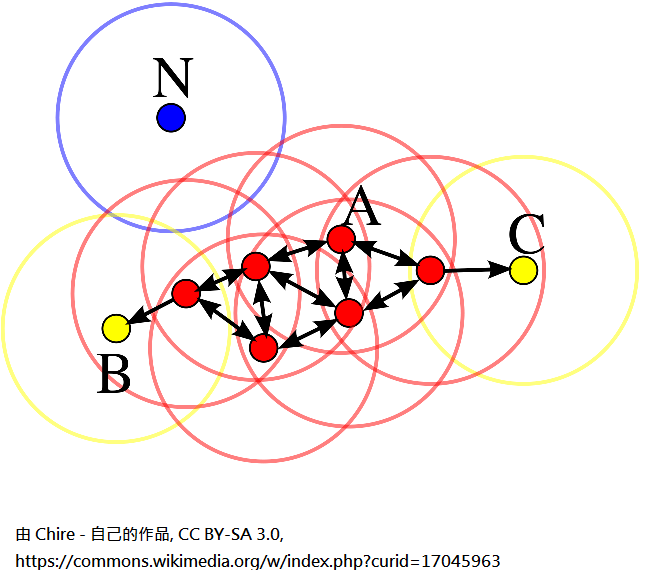
上圖中有九個資料點進行 DBSCAN 聚類,其中的 ε-鄰域我們已經用視覺化的方式展現出來,minPts 設為 4。 可以看到其中的 N 點為明顯得孤立點,即在其 ε-鄰域中無其他資料點;而 B 與 C 雖然在它們的 ε-鄰域有其他的資料點,但是並不滿足minPts為4的門檻,故也不會被加入聚類內。 值得注意的是,從 A 點本身的 ε-鄰域來看,它也不滿足 minPts 為 4 的門檻,但是它在其他滿足 minPts 為 4 的 ε-鄰域中被發現,所以最後也被加入的聚類當中。 看到這邊,大致上可以了解 DBSCAN 演算法在使用上有以下幾個特點:
但是有利就有弊,DBSCAN 當然也不是無懈可擊的,常見的缺點有:
最後 Coding 的話,如果選擇使用現成函式庫(e.g. scikit-learn)來做的話還蠻簡單的,只要將函式庫引入、設定好 minPts & ε 這兩個參數,再把你的資料 fit 近去就好了,範例代碼如下:
DBSCAN example with sklearn
其中的 eps 就是我們的 ε;min_samples 就是 minPts;X是我們隨機模擬出來的資料點,最後我們聚類出來的標籤為 array([ 0, 0, 0, 1, 1, -1]),即表示說演算法將 [1,2]、[2,2]、[2,3] 這三個點聚為一類,[8,7]、[8,8] 這兩個點聚為一類,而 [25,80] 這個點被判定成 Noise。
至於 sklearn 關於 DBSCAN 比較詳細的用法與解說可以參考它的官方文件: https://scikit-learn.org/stable/modules/generated/sklearn.cluster.DBSCAN.html Ok,那對於 DBSCAN 的介紹就先寫到這邊,感謝收看。
0 評論
發表回覆。 |
Jason Chen人不光是生來就擁有一切,而是靠他從學習中得到的一切來造就自己。- 歌德 文章分類
全部
封存檔
九月 2023
|
